The capital of France is ___
当大模型生成一个新单词时,模型内部的矩阵大小到底是如何变化的?
Embedding 嵌入层
我们从嵌入层(embedding layer)开始。假设一个单词等于一个token。
输入句子:The capital of France is ___
-> [‘The’, ‘capital’, ‘of’, ‘France’, ‘is’]
-> [464, 3361, 295, 2238, 318], 这是他们的Token ID
我们得到一个长度为5的向量。
GPT-2是最适合拆解的模型,其他的模型原理都类似。
GPT-2采用 50000 词汇表,每个 token 映射为 768 维向量。
也就是说,这时候会有一个size是[50000, 768]的表格(aka 嵌入表, embedding table)。
根据这个表格,
- The = [0.316, 0.524,0.063, 0.481, 0.266, …]
- capital = [0.123, 0.234, 0.345, 0.456, 0.567, …]
- of = [0.432, 0.543, 0.654, 0.765, 0.876, …]
- France = [0.543, 0.654, 0.765, 0.876, 0.987, …]
- is = [0.654, 0.765, 0.876, 0.987, 0.098, …]
-> 最终得到一个 [5, 768] 的矩阵!
Attention
在 GPT-2 中,多头注意力(Multi-Head Attention) 的 head 数量 为 12。
我们得到一个数学关系就是12 * 64 = 768。
所以[5, 768] == [5, 12, 64] == [5, 64] * 12
这里我们会有三个大关键矩阵:Q矩阵, K矩阵, V矩阵。每一个都是[768, 768]。
先从Q矩阵开始。
由于Q矩阵的size是[768, 768] == [768, 12 * 64]。
我们把其中一个768拆成12个head,每个头都是[768, 64]。
Q一个head = [5, 768] * [768, 64] = [5, 64]
Q = 12个头 = [5, 64] + [5, 64] + … + [5, 64] = [5, 12 * 64] = [5, 768]
K矩阵和V矩阵同理。
K = [5, 768]
V = [5, 768]
这里祭出那个最重要的attention公式:
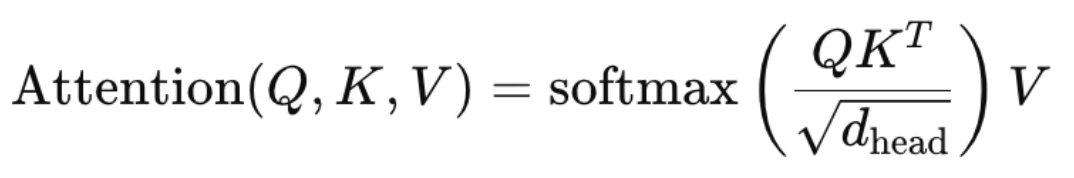
Q = [5, 768]
K^T = [768, 5]
QK^T = [5, 5]
Softmax(QK^T/√d) = [5, 5]
Softmax(QK^T/√d) * V = [5, 768]
这里我们还有一个 输出投影矩阵 Output Projection matrix = [768, 768], 不会改变V的size。
Output projection(A) = [5, 768] * [768, 768] = [5, 768]
最终还是[5, 768]。
全连层 Multi-Layer Perceptron (MLP)
Attention output = [5, 768]
MLP有两层: 一层扩展 [768 × 3072] 一层缩回 [3072 × 768]
变化:[5, 768] -> [5, 3072] -> [5, 768]
最终又是[5, 768]。
再次Attention 再次MLP 一共12次
(5, 768) -> (5, 768) -> (5, 768) … -> (5, 768)
最最终还是 [5, 768]。
输出
取最后一行得到[768]
再用一开始的那个[50000, 768]的表格找回Token Id,然后找回单词 = Paris
参数量计算
50000 * 768 + (768 * 768 * 3 + 768 * 768 + 768 * 3072 * 2) * 12
= 38.4M + (7.08M) × 12 = 124M
他们分别对应: 嵌入层(50000, 768), KQV 矩阵(768, 768), 输出矩阵(768, 768), 全连层(768, 3072) * 2, 共12次
参数总数:
- 38.4M → Embedding 层
- 21.2M → KQV 矩阵
- 7.1M → 输出投影矩阵
- 56.6M → MLP 层
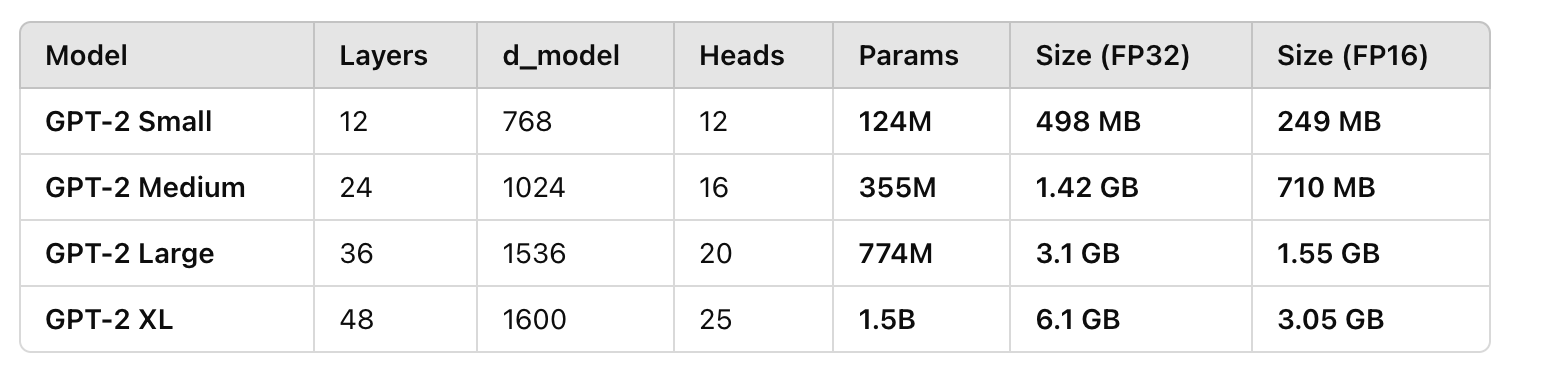
附一个gpt2小中大的参数量对比:
总结
- Embedding层将句子转换为[5, 768]的向量。
- 多头注意力机制 计算 Q, K, V 三个[5, 768]
- 通过 Softmax(QK^T / sqrt(d)) * V 计算新的[5, 768]。
- MLP 进行维度扩展和缩回, 又得到新的[5, 768]。
- 重复 12 层 Transformer 计算,最终输出[5, 768]。
- 投影回词汇表 并 Softmax 选词,得到最终结果”Paris”。
- 参数量 ~124M,主要分布在 Embedding、Attention 和 MLP 组件中。
注意这个5是句子长度,真实的生成过程会padding到最大长度1024。
768是每个token的维度, aka d_model。
12是多头注意力的head数量, aka h。
12也是Transformer的层数, aka n_layers。
还是非常神奇的!写好之后回看了很多次,好奇这为什么产生智慧,依然觉得这个过程非常神奇!
马上会写一个所有知名模型(chatgpt, claude, llama, deepseek, qwen, etc)参数的拆解。诶, 我怎么把Gemini忘了?