The capital of France is ___
When a large model generates a new word, how do the matrices inside the model change?
Embedding
We start with the embedding layer. Assume one word equals one token.
Input sentence: The capital of France is ___
-> [‘The’, ‘capital’, ‘of’, ‘France’, ‘is’]
-> [464, 3361, 295, 2238, 318], which are their Token IDs
This forms a sequence of length 5.
GPT-2 is the best model for breakdowns, as other models follow similar principles.
GPT-2 has a vocabulary of 50,000 tokens, with each token mapped to a 768-dimensional vector.
This means there exists an embedding table of size [50,000, 768].
Looking up the embedding table:
- The = [0.316, 0.524,0.063, 0.481, 0.266, …]
- capital = [0.123, 0.234, 0.345, 0.456, 0.567, …]
- of = [0.432, 0.543, 0.654, 0.765, 0.876, …]
- France = [0.543, 0.654, 0.765, 0.876, 0.987, …]
- is = [0.654, 0.765, 0.876, 0.987, 0.098, …]
-> Thus, we obtain a [5, 768] matrix!
Attention
In GPT-2 small, Multi-Head Attention has 12 heads.
A key mathematical relationship: 12 * 64 = 768.
So [5, 768] == [5, 12, 64] == [5, 64] * 12
We will have three key matrices: Q, K, V. Each is [768, 768].
Let’s start with Q.
Since Q’s size is [768, 768] == [768, 12 * 64].
We split one of the 768 into 12 heads, each of which is [768, 64].
Q one head = [5, 768] * [768, 64] = [5, 64]
Q = 12 heads = [5, 64] + [5, 64] + … + [5, 64] = [5, 12 * 64] = [5, 768]
K and V are the same.
K = [5, 768]
V = [5, 768]
Here’s the most important attention formula:
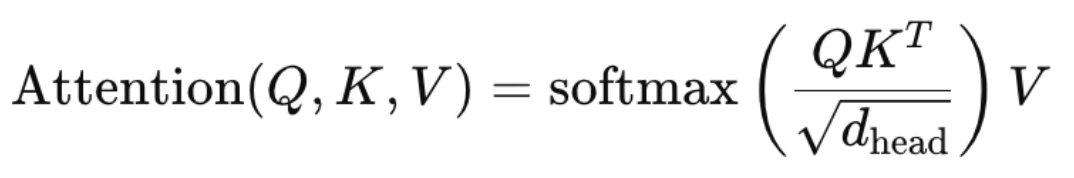
Q = [5, 768]
K^T = [768, 5]
QK^T = [5, 5]
Softmax(QK^T/√d) = [5, 5]
Softmax(QK^T/√d) * V = [5, 768]
We also have an output projection matrix = [768, 768], which does not change the size of V.
Output projection(A) = [5, 768] * [768, 768] = [5, 768]
This is still [5, 768].
Multi-Layer Perceptron (MLP)
Attention output = [5, 768]
MLP has two layers: one expands [768 × 3072] and one contracts [3072 × 768]
Change: [5, 768] -> [5, 3072] -> [5, 768]
This is still [5, 768].
Repeating Attention + MLP for 12 Layers
(5, 768) -> (5, 768) -> (5, 768) … -> (5, 768)
This is still [5, 768].
Final Output
We extract the last row: [768]
Then, we use the original embedding table [50,000, 768] to map back to a Token ID, retrieving the final word: Paris
Parameter Count Calculation
50000 * 768 + (768 * 768 * 3 + 768 * 768 + 768 * 3072 * 2) * 12
= 38.4M + (7.08M) × 12 = 124M
They are: embedding(50000, 768), KQV weights(768, 768), output projection(768, 768), MLP weights(768, 3072) * 2, for 12 layers.
Breakdown of Parameters:
- 38.4M → Embedding
- 21.2M → KQV matrix
- 7.1M → Output Projection
- 56.6M → MLP
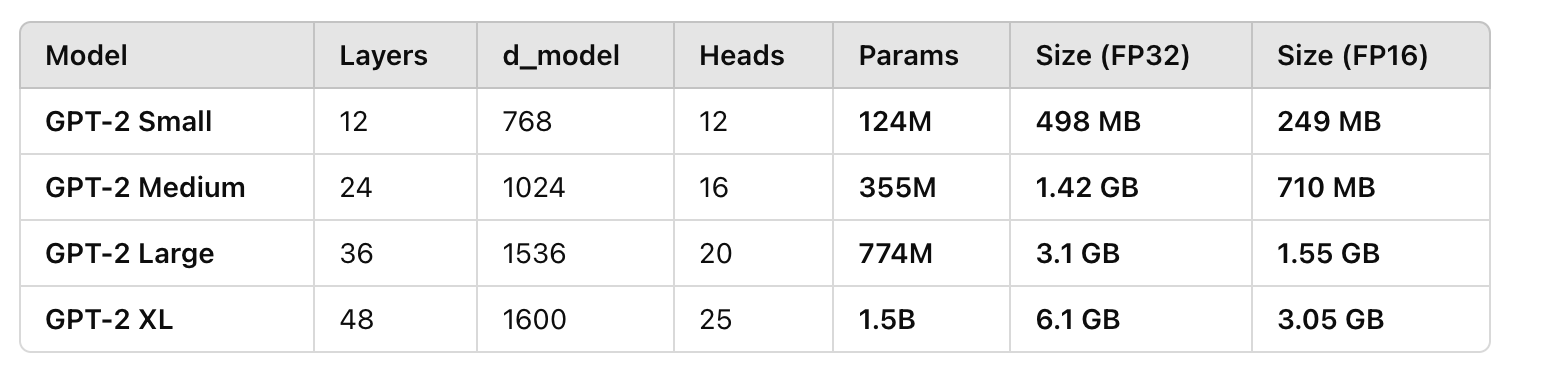
A comparison of GPT-2 model sizes:
Summary
- The embedding layer converts the sentence into a [5, 768] matrix.
- The multi-head attention mechanism calculates Q, K, V, all with shape [5, 768].
- Applying Softmax(QK^T / sqrt(d)) * V gives a new [5, 768].
- The MLP expands and contracts dimensions, outputting another [5, 768].
- Repeating this process for 12 Transformer layers keeps the final shape [5, 768].
- The last row [768] is mapped back to a token using the embedding table.
- The final predicted word: “Paris”.
- Total parameters ~124M, primarily distributed across Embedding, Attention, and MLP.
Note that the 5 is the sentence length, and the actual generation process pads to the max length, 1024.
768 is the dimensionality of each token, also known as d_model.
12 is the number of attention heads, also referred to as h.
12 is also the number of Transformer layers, known as n_layers.
This entire process is truly fascinating! Even after writing and reviewing it multiple times, I still find it incredible how this leads to intelligence. The way these transformations give rise to meaningful text remains a mystery!
I’ll write a comparison of famous models’ (chatgpt, claude, llama, deepseek, qwen, etc) parameters composition soon! Wait, did I forget Gemini?