法国的首都是___
当大模型生成一个新词时,模型内部的矩阵是如何变化的?
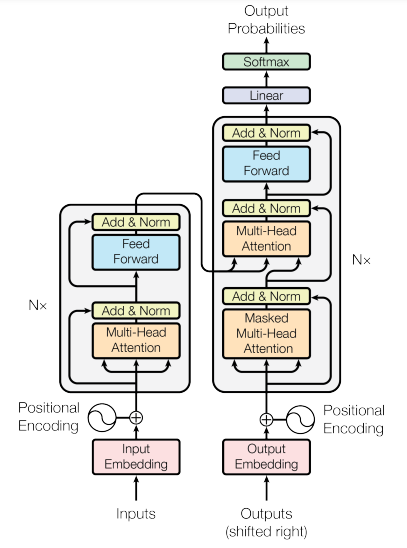
上图来自”Attention is all you need”论文,非常直观地展示了transformer的运作原理。但模型内部究竟发生了什么?
矩阵乘法
让我们先看看矩阵乘法。注意两个矩阵的维度是如何匹配的,我们将在下面的可视化中使用这种模式。
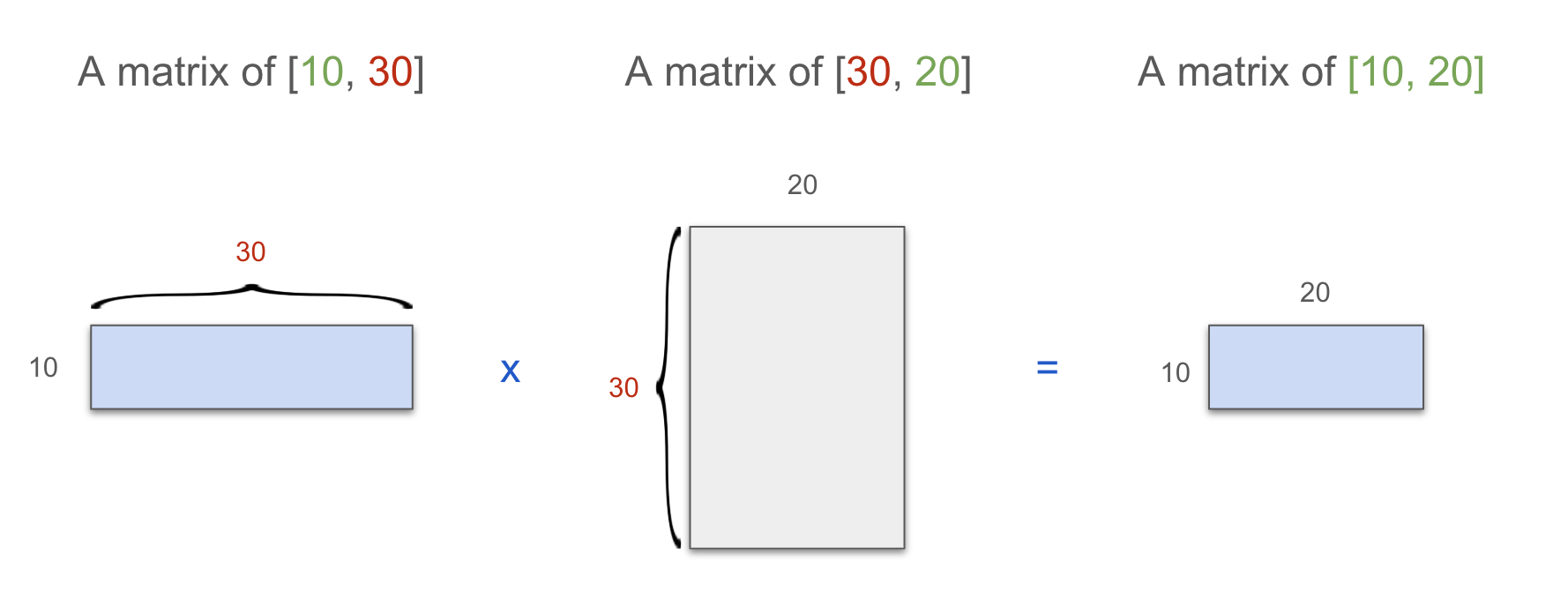
蓝色:数据(张量) 灰色:模型权重
嵌入层
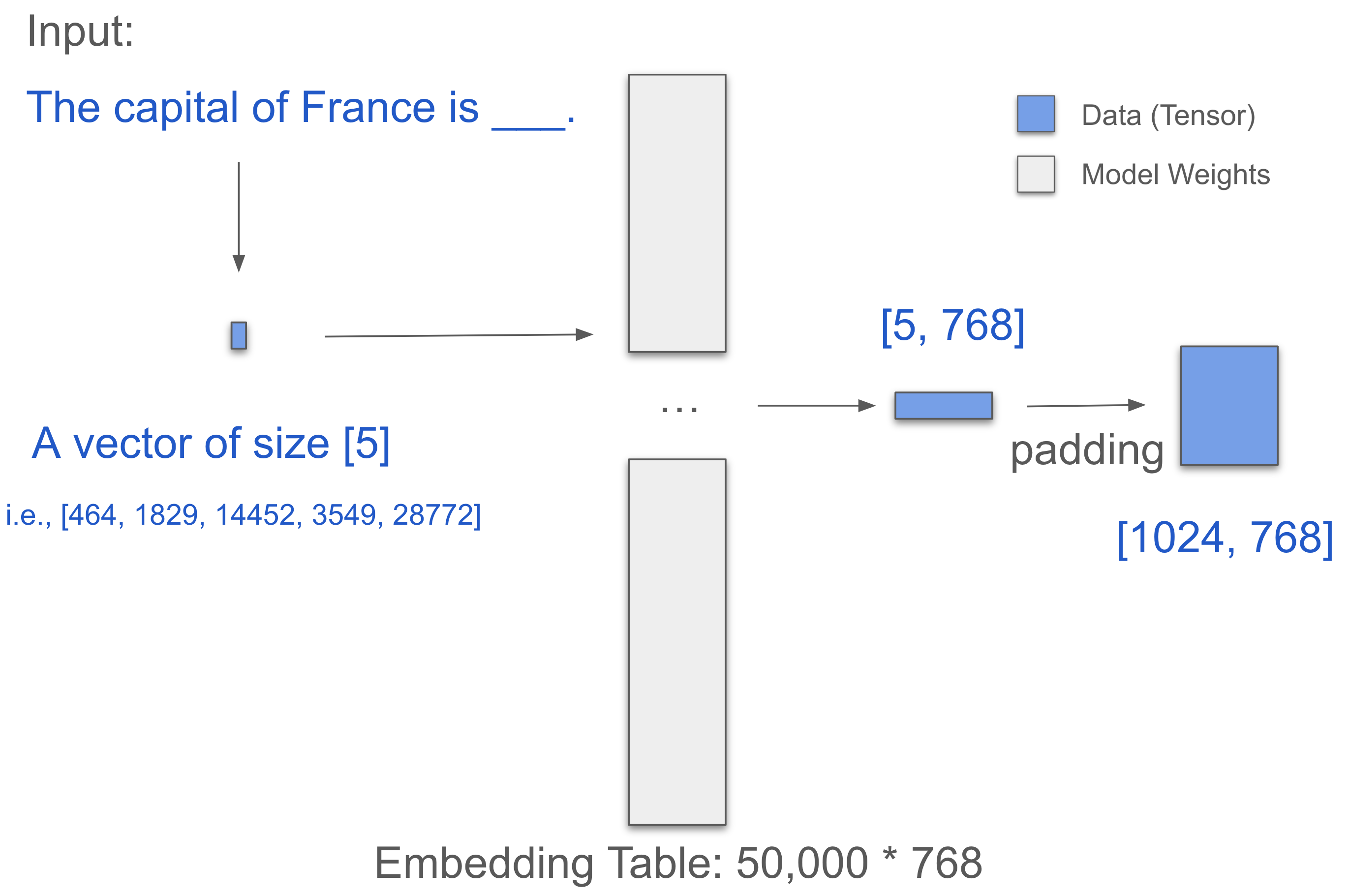
我们从嵌入层开始。假设一个词等于一个token。
输入句子:法国的首都是___
-> [‘法国’, ‘的’, ‘首都’, ‘是’]
-> [2238, 295, 3361, 318],这些是它们的Token ID
这形成了一个[1, 4]向量。
数据现在进入大小为[50,000, 768]的嵌入表进行查找:
- The = [0.316, 0.524, 0.063, …]
- capital = [0.123, 0.234, 0.345, …]
- of = [0.432, 0.543, 0.654, …]
- France = [0.543, 0.654, 0.765, …]
- is = [0.654, 0.765, 0.876, …]
-> 这样我们得到了一个[5, 768]矩阵!
填充(附加一些0)到长度1024,现在变成了[1024, 768]。
Transformer块
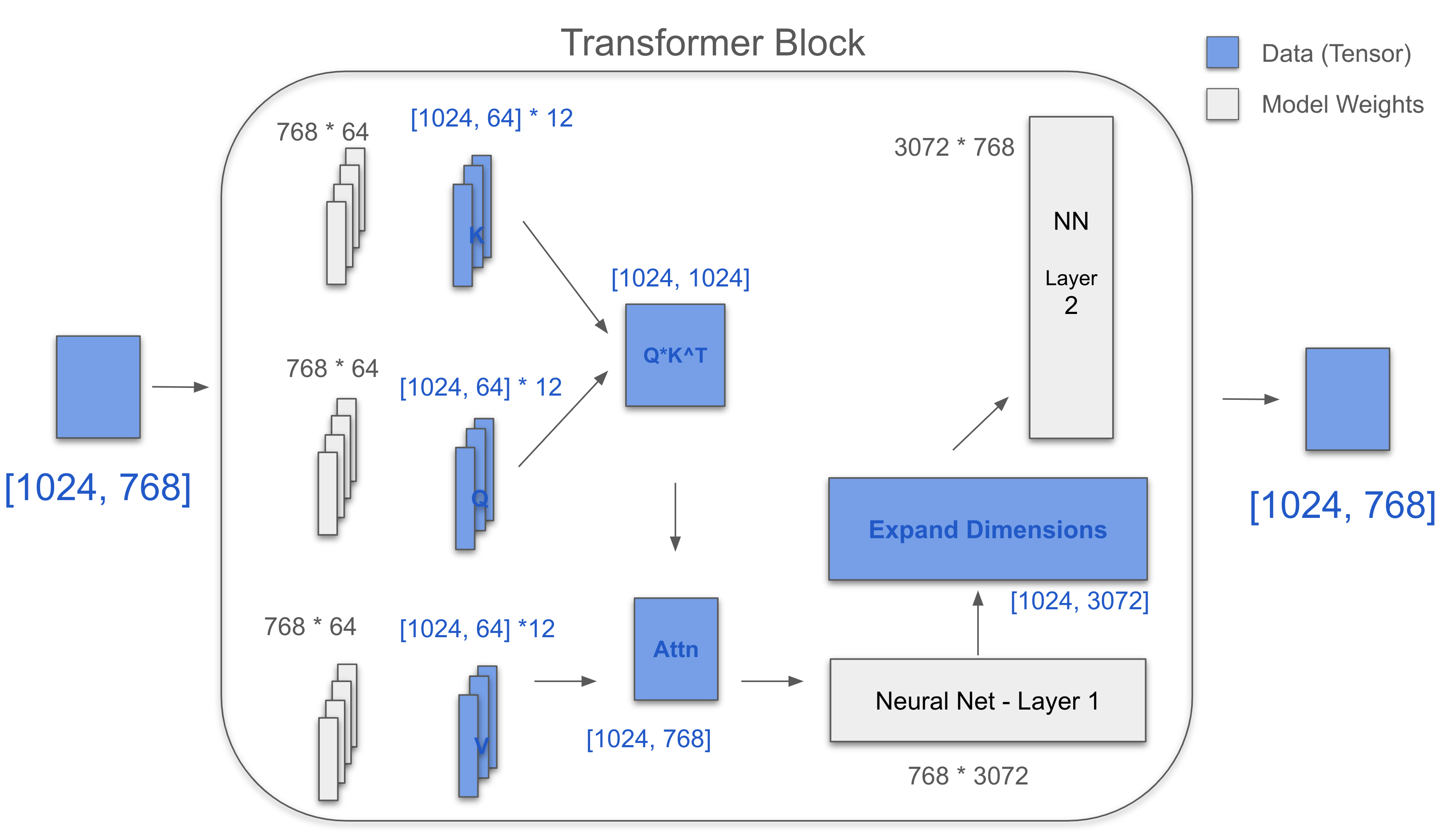
三个关键矩阵:Q、K、V。每个都是[768, 64] * 12。
对于一个注意力头,[1024, 768] * [768, 64] = [1024, 64]
Q的12个头 = [1024, 64] + [1024, 64] + … + [1024, 64]
= [1024, 64] * 12 = [1024, 768]
K和V也是一样的。
K^T = [768, 1024]
QK^T = [1024, 1024]
Softmax(QK^T/√d) = [1024, 1024]
Attn = Softmax(QK^T/√d) * V = [1024, 768]
MLP有两层:一层使用[768 × 3072]扩展4倍,一层使用[3072 × 768]收缩
变化:[1024, 768] -> [1024, 3072] -> [1024, 768]
整个过程
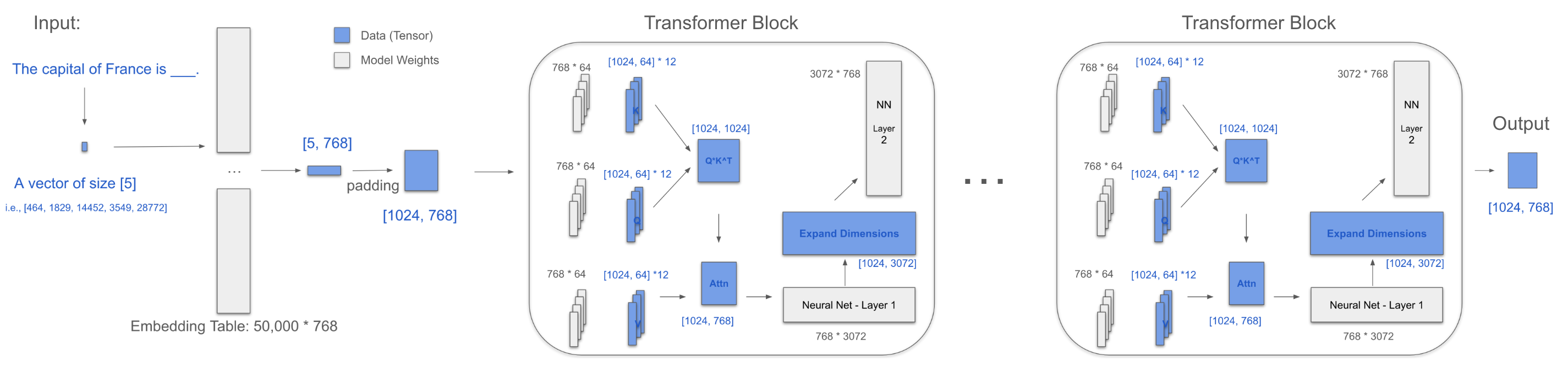
提取最后一行:[768]
然后,使用原始的嵌入表[50,000, 768]映射回Token ID,得到最终的词:Paris
模型参数
所有的transformer模型都有类似的结构,只是层数(12)、d_model(768)、d_head(64)等参数不同。附录展示了著名模型的参数数量。最新的研究致力于使用不同的注意力机制(如MLA、NSA)来减少参数总数,这不是本文的重点。
感谢阅读!🎉 🥰 🫡
附录:参数数量
注意:以下参数是由AI辅助生成,尚未经过仔细的人工验证。
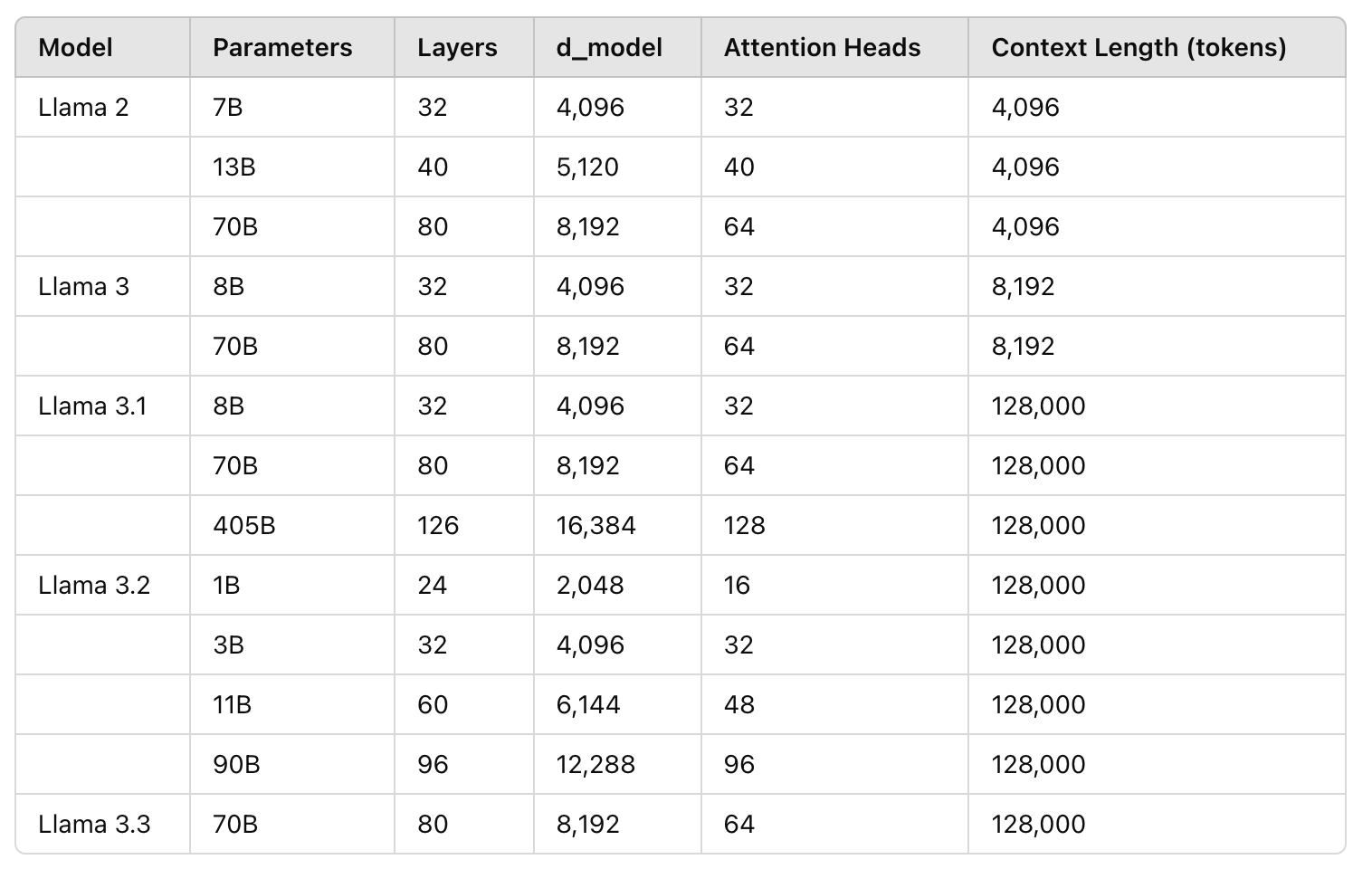
Llama系列
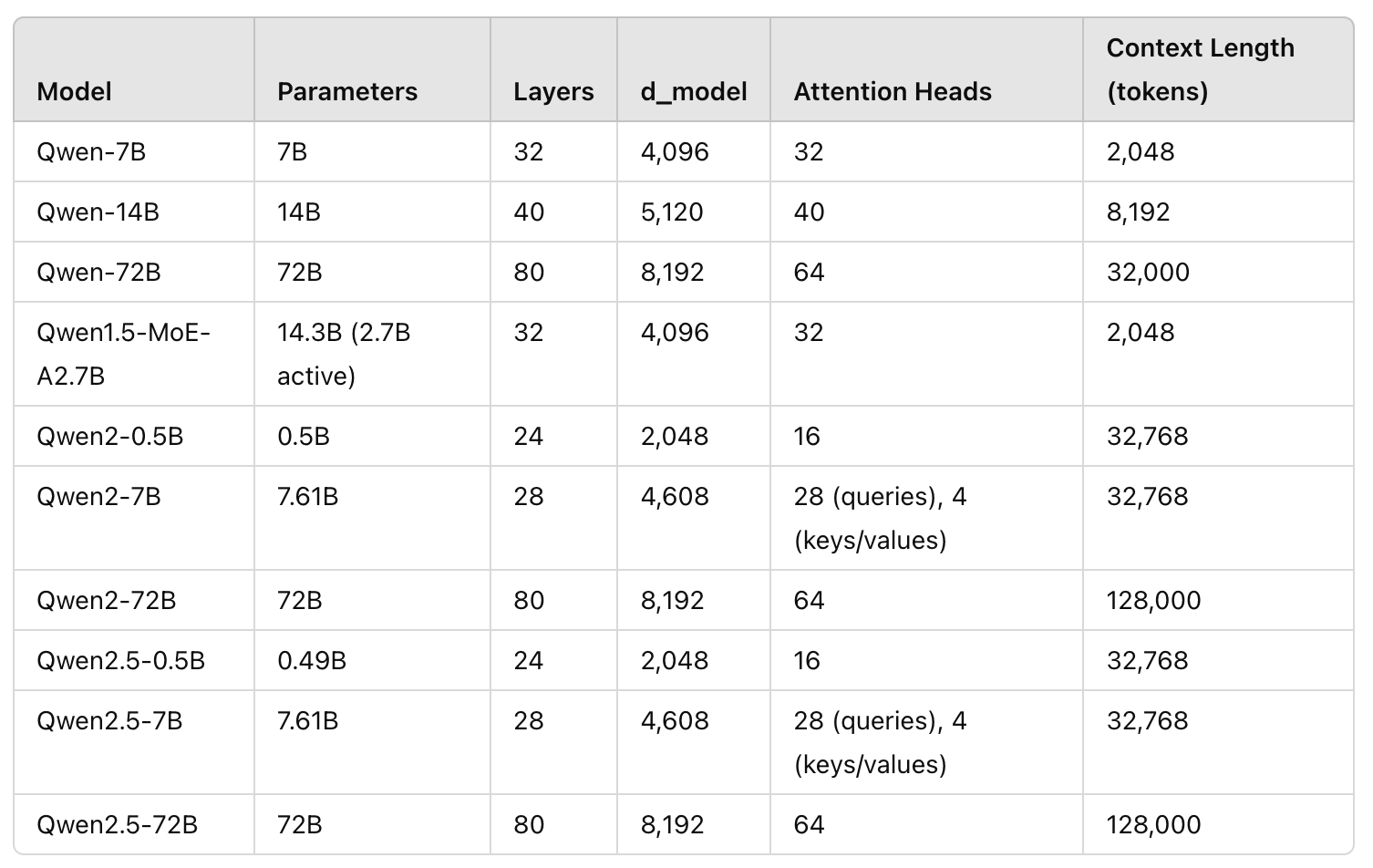
Qwen系列
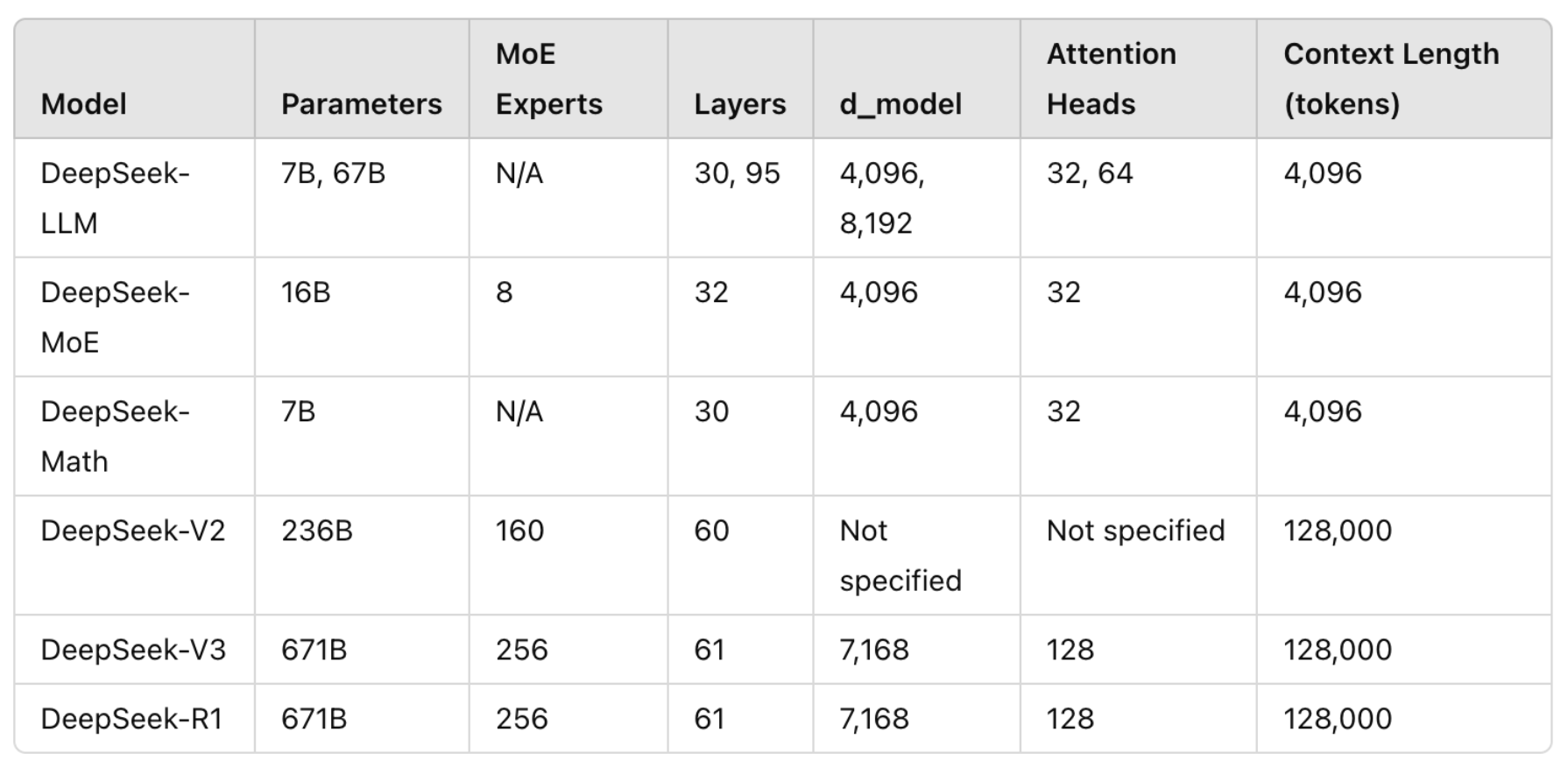
DeepSeek系列
ChatGPT系列
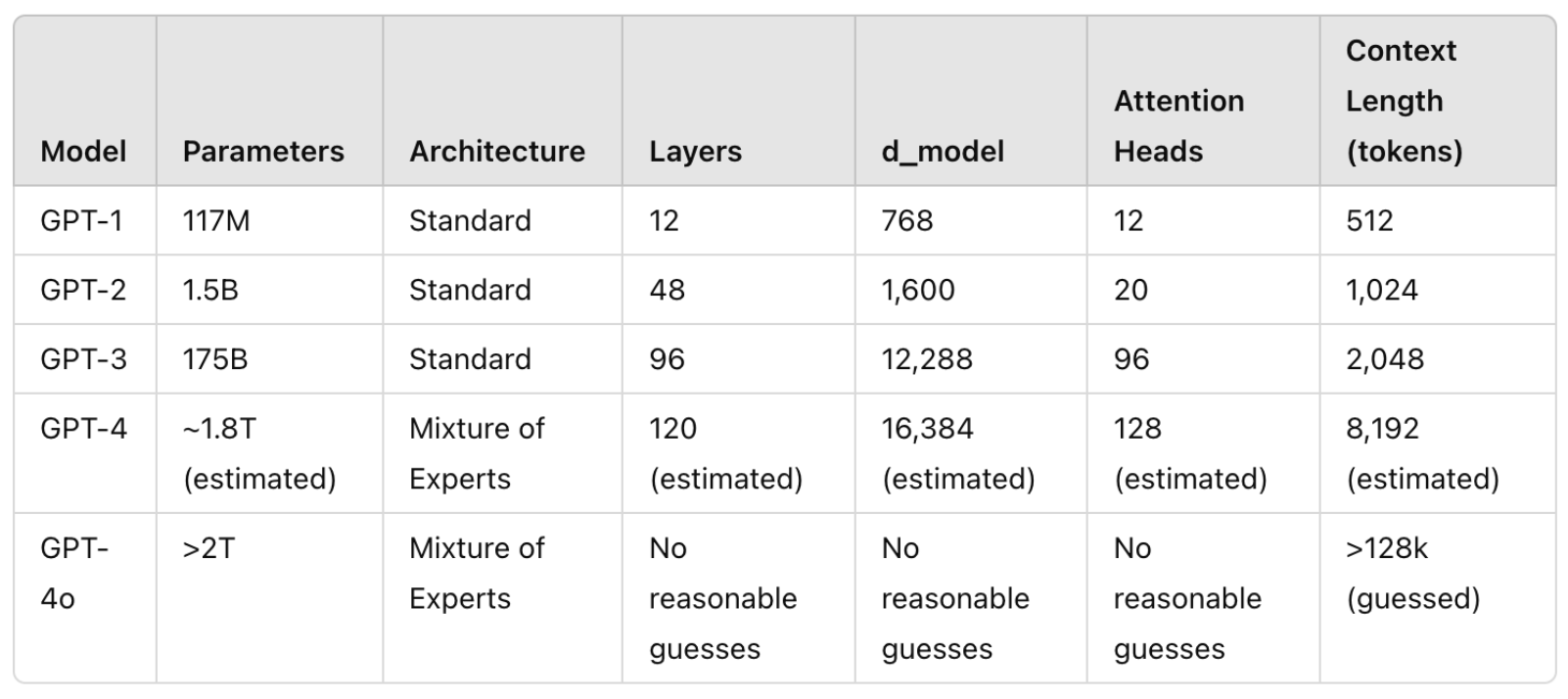
其他
鉴于Claude和Gemini是闭源的,仅展示对其参数的猜测并没有太大价值。同样地,对于刚刚发布的Grok-3,让我们拭目以待!