The capital of France is ___
When a large model generates a new word, how do the matrices inside the model change?
Matrix Multiplication
Let’s visualize matrix multiplication first. Note how the dimensions of the two matrices are matched, we will use this pattern in below visualizations.
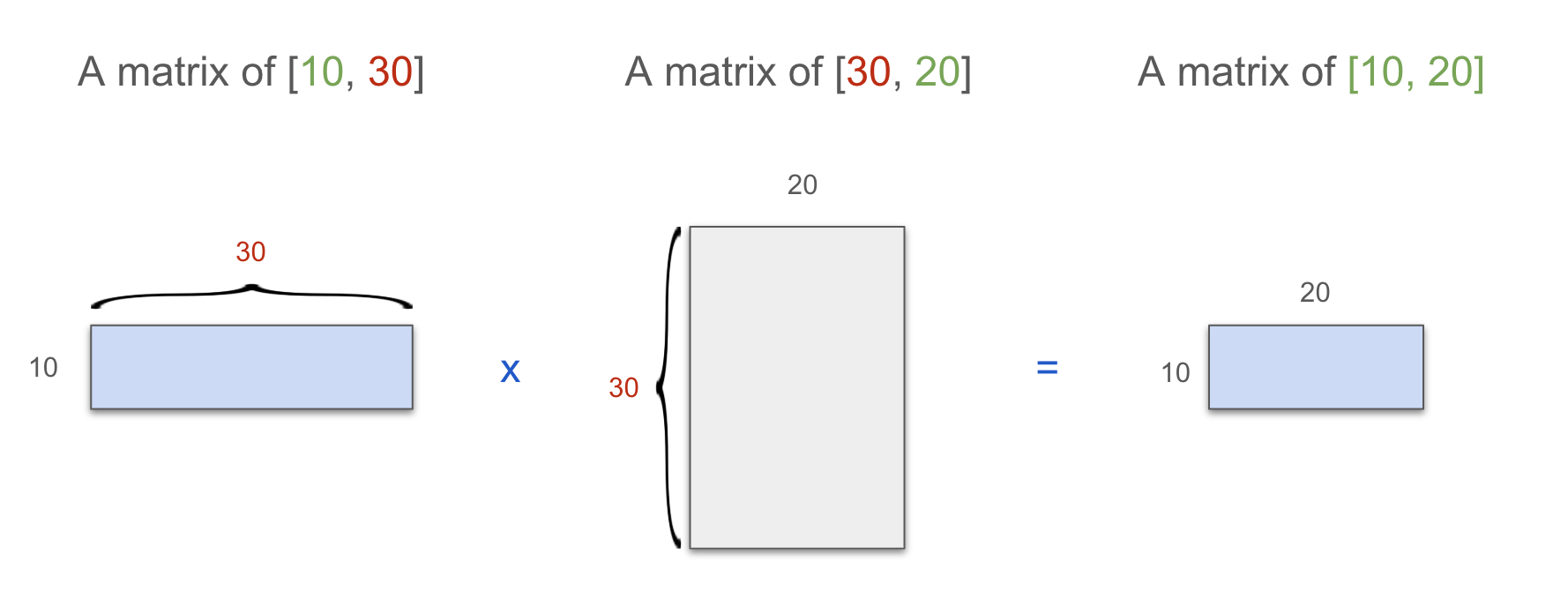
Blue: Data (Tensor)
Grey: Model Weights
Embedding
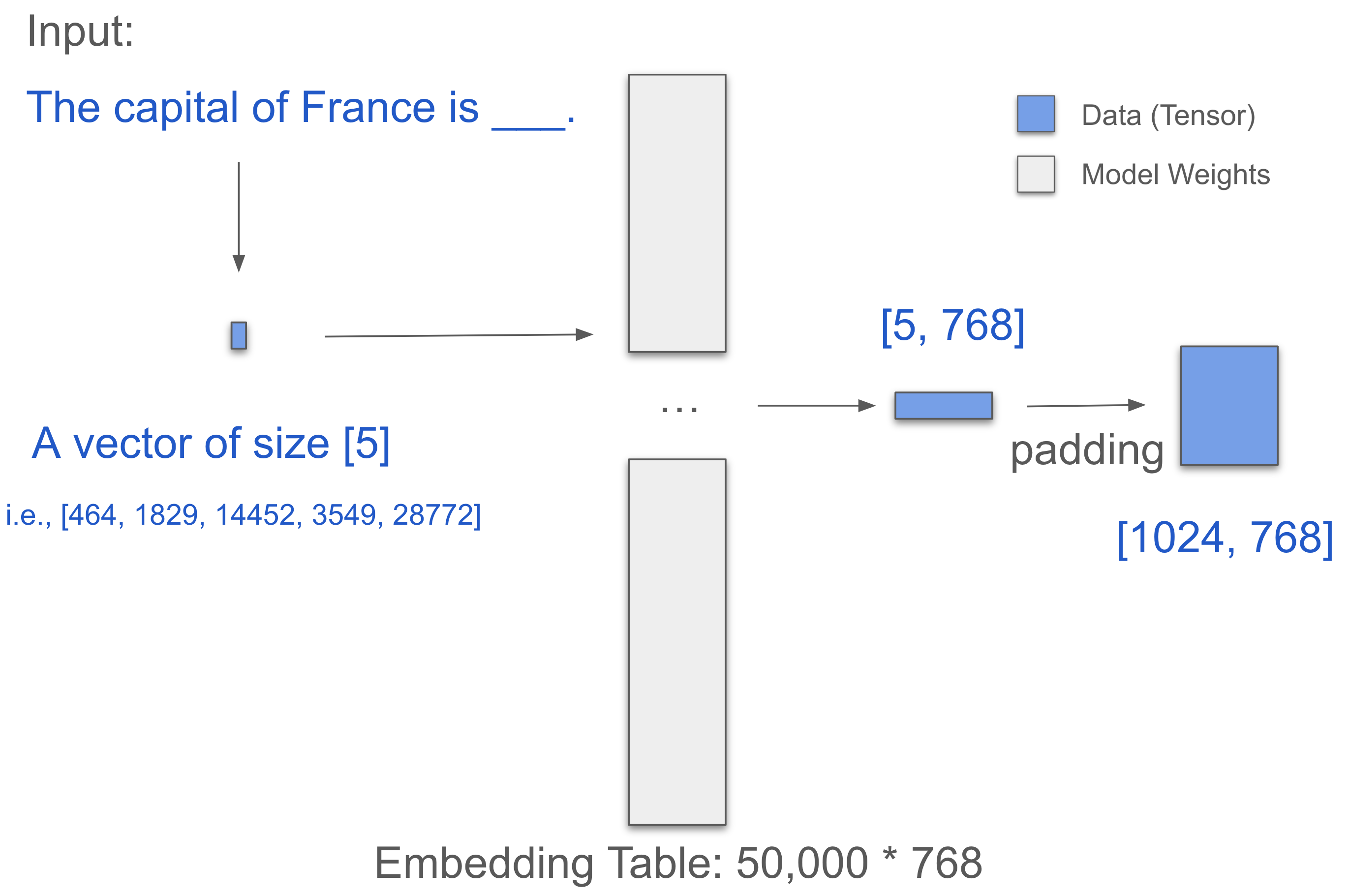
Start with the embedding layer. Assume one word equals one token.
Input sentence: The capital of France is ___
-> [‘The’, ‘capital’, ‘of’, ‘France’, ‘is’]
-> [464, 3361, 295, 2238, 318], which are their Token IDs
This forms a [1, 5] vector.
The data now enters an embedding table of size [50,000, 768] to look up:
- The = [0.316, 0.524, 0.063, …]
- capital = [0.123, 0.234, 0.345, …]
- of = [0.432, 0.543, 0.654, …]
- France = [0.543, 0.654, 0.765, …]
- is = [0.654, 0.765, 0.876, …]
-> Thus, we obtain a [5, 768] matrix!
We pad (appending 0s) it to length 1024, which now becomes [1024, 768].
Transformer Block
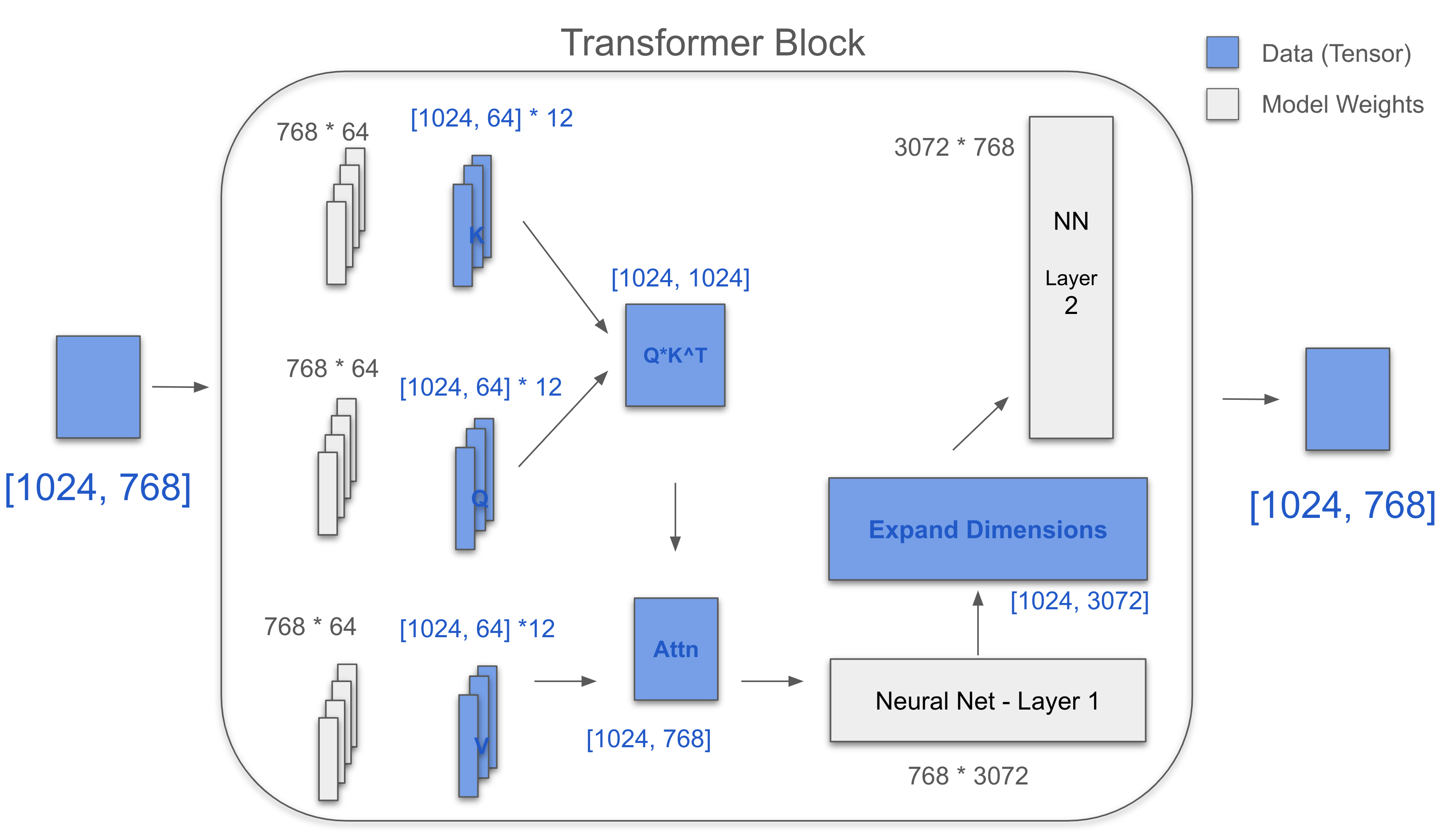
Three key matrices: Q, K, V. Each is [768, 64] * 12.
For one head, [1024, 768] * [768, 64] = [1024, 64]
Q 12 heads = [1024, 64] + [1024, 64] + … + [1024, 64]
= [1024, 64] * 12 = [1024, 768]
K and V are the same.
K^T = [768, 1024]
QK^T = [1024, 1024]
Softmax(QK^T/√d) = [1024, 1024]
Attn = Softmax(QK^T/√d) * V = [1024, 768]
MLP has two layers: one expands 4x using [768 × 3072] and one contracts using [3072 × 768]
Change: [1024, 768] -> [1024, 3072] -> [1024, 768]
The Whole Process
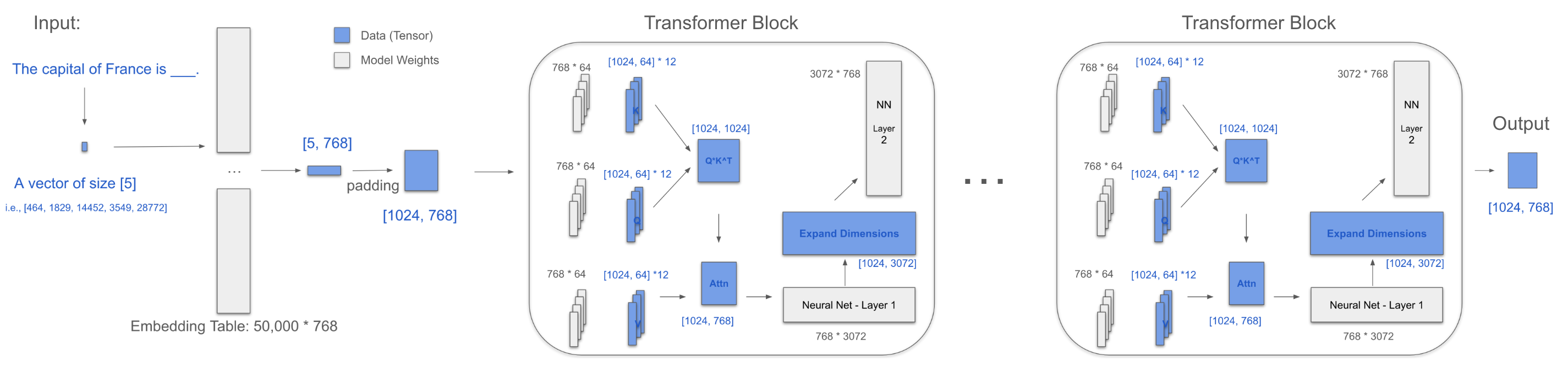
Extract the last row: [768]
Then, use the original embedding table [50,000, 768] to map back to a Token ID, retrieving the final word: Paris
Parameters of Models
All the transformer models have a similar structure, just different numbers of layers(12), d_model(768), d_head(64), etc. The appendix shows the number of parameters for the famous models.
Latest research aims to reduce the total number of parameters using different attention mechanisms (e.g., MLA, NSA), which is not the focus of this article.
Thank you for reading! 🎉 🥰 🫡
Appendix: Number of Parameters
Note below tables are assisted by AI, and not manually verified carefully.
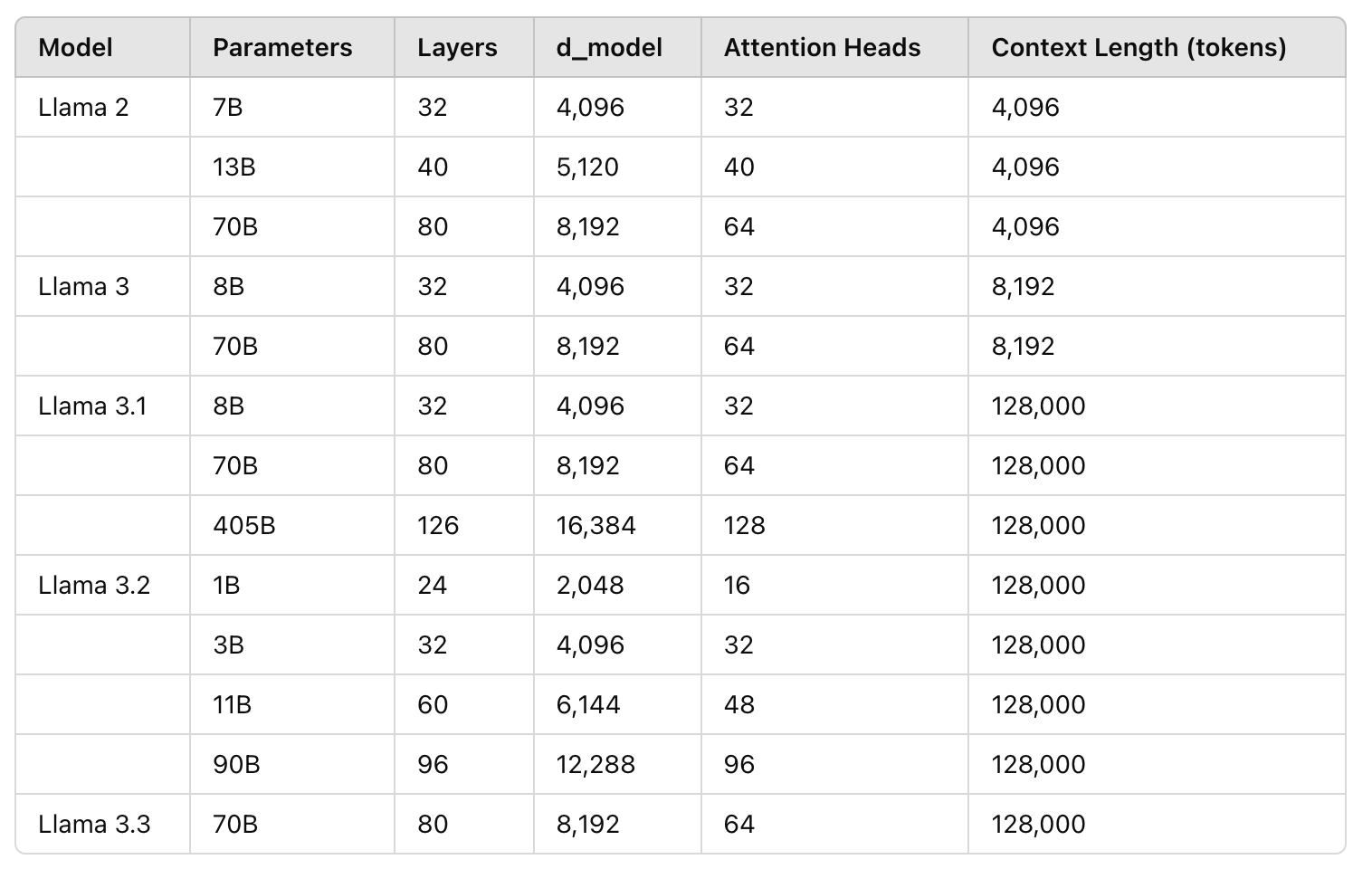
Llama Family
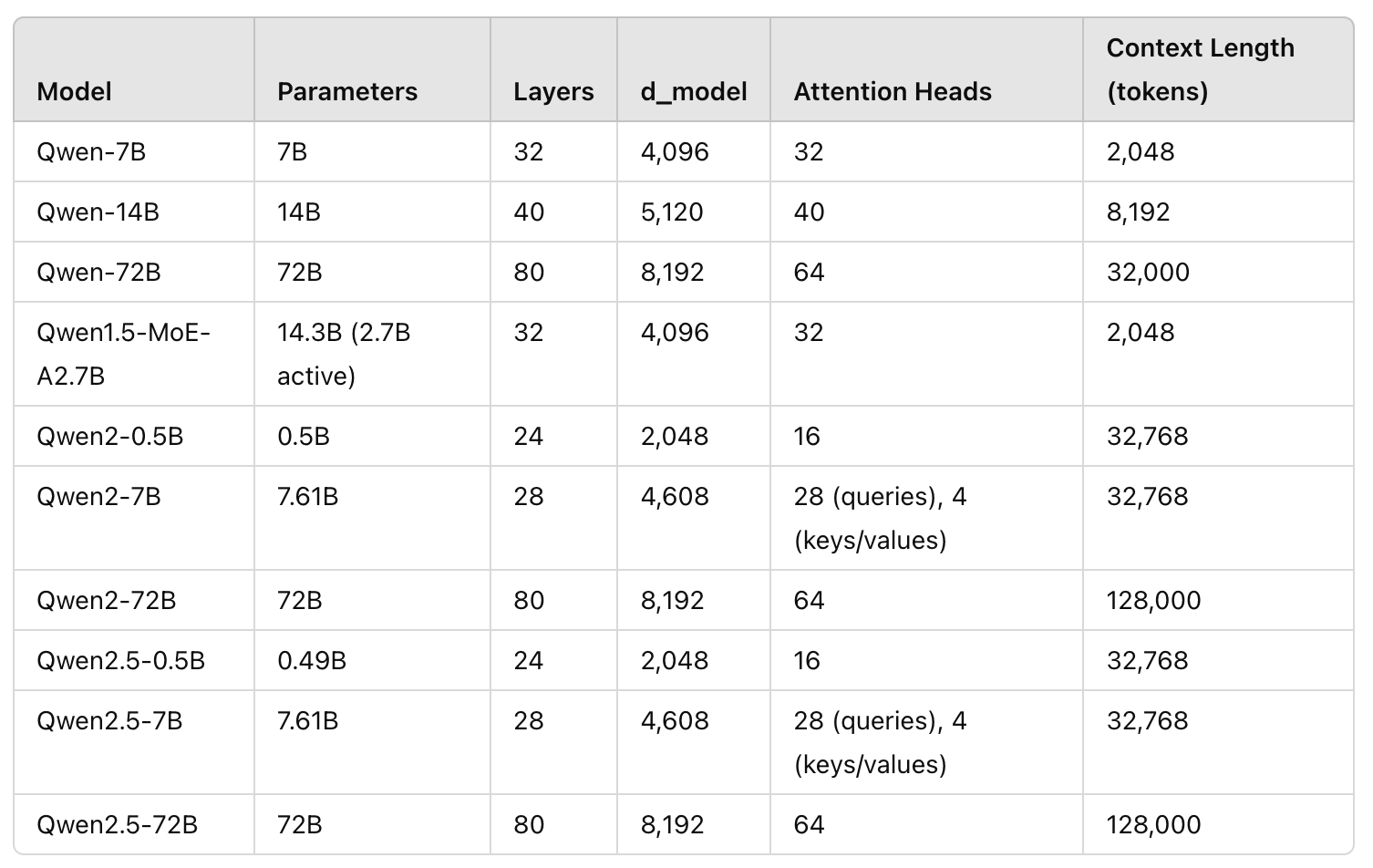
Qwen Family
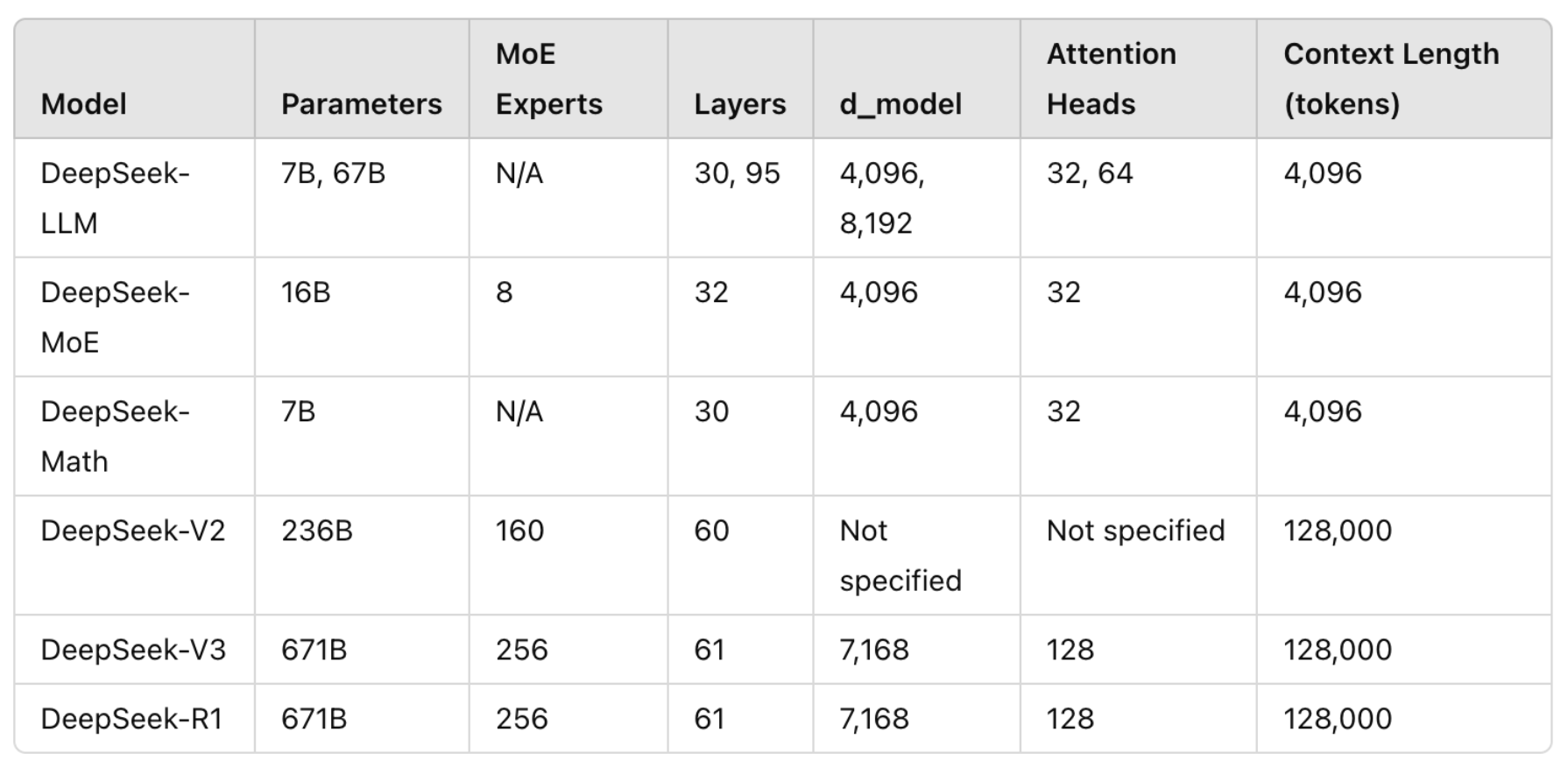
DeepSeek Family
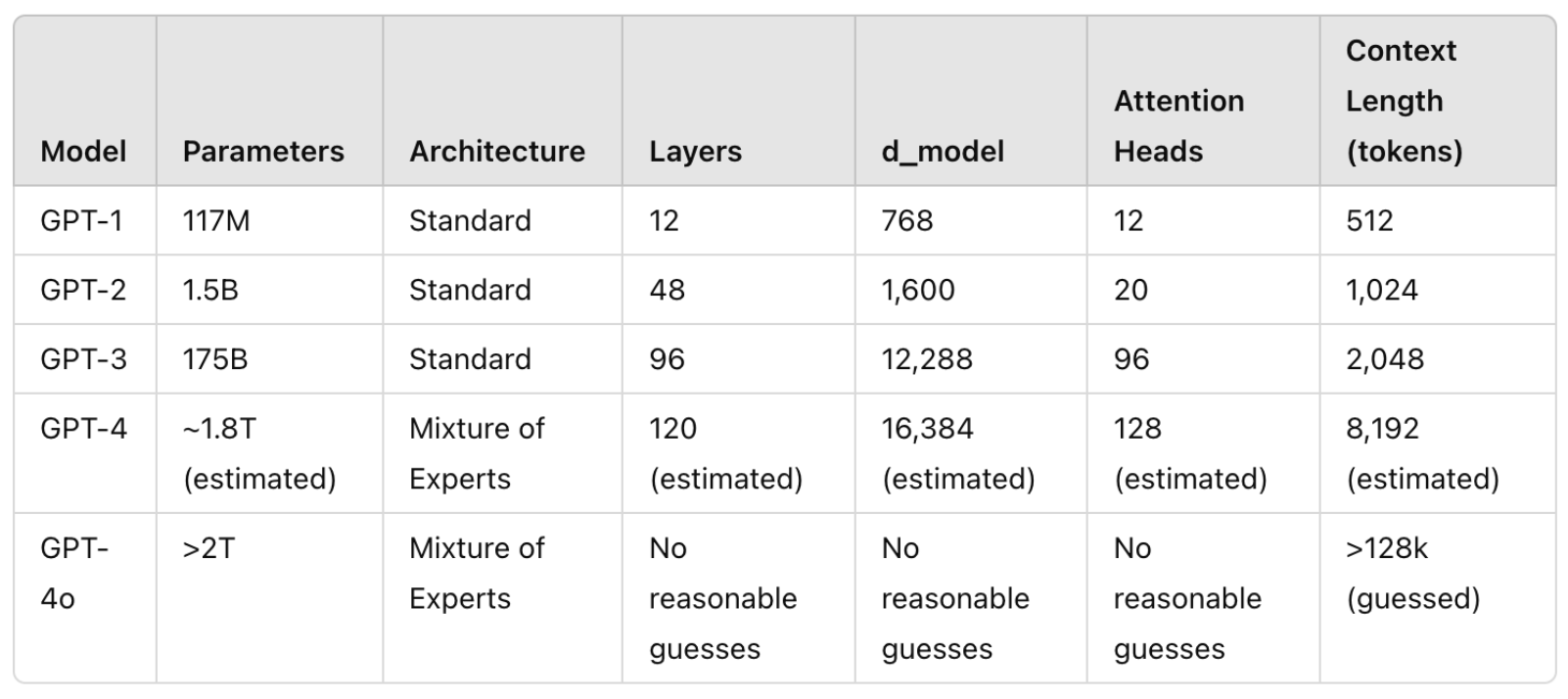
ChatGPT Family
Other
Given Claude and Gemini are closed source, it does not provide much value just showing the guesses. Same for Grok, Grok-3 just got released. Let’s wait and see!