The Introduction
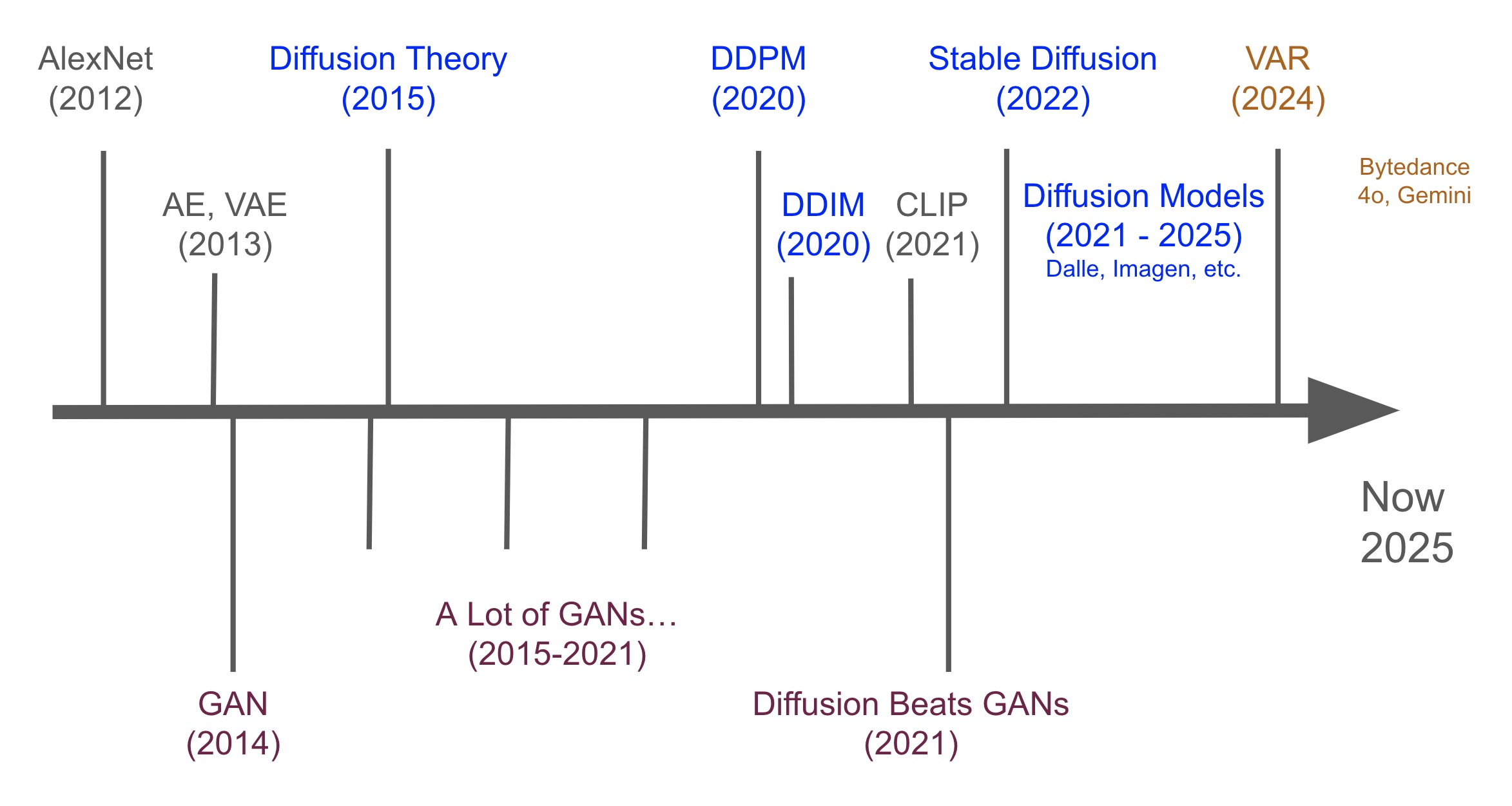
It’s crucial to introduce the history of image generation milestones concisely. The field can seem noisy, with many reports of ‘good’ results from various works. The good news is, you find this article. While not exhaustive, it’s designed to give you a strong intuition behind the key developments and focuses squarely on the latest advancements.
To even simplify the history, we can divide the history into 3 eras: VAE, GAN, Diffusion. And maybe the 4th one, VAR era given VAR is getting popular recently.
- AlexNet (2012):
- “ImageNet Classification with Deep Convolutional Neural Networks” by Krizhevsky, Sutskever, and Hinton.
- Significance: The classic paper that marks the start of Deep Learning era. Demonstrated the power of Convolutional Neural Networks (CNNs), paving the way for their use in more complex generative models.
- Autoencoders (AEs):
- Concept evolved over decades (early work by LeCun, Hinton et al.).
- “Reducing the Dimensionality of Data with Neural Networks” by Hinton, G. E. (2006).
- Significance: A seminal work that introduced the concept of autoencoders, which are neural networks designed for unsupervised learning, primarily for dimensionality reduction or feature learning.
- Variational Autoencoders (VAEs):
- “Auto-Encoding Variational Bayes” by Kingma & Welling (Dec 2013)
- “Stochastic Backpropagation and Approximate Inference in Deep Generative Models” by Rezende et al. (Jan 2014).
- Significance: Provided a principled probabilistic framework for learning deep latent variable models capable of generating new data, by regularizing the latent space.
- GAN (2014):
- Generative Adversarial Networks: Introduced by Ian Goodfellow et al. (June 2014).
- Significance: A groundbreaking framework where two neural networks, a Generator and a Discriminator, compete against each other. The Generator tries to create realistic data, while the Discriminator tries to distinguish real data from generated data. This adversarial process led to significant improvements in the realism and sharpness of generated images compared to earlier methods like VAEs.
- Diffusion Models Theory (2015):
- “Deep Unsupervised Learning using Nonequilibrium Thermodynamics” by Sohl-Dickstein et al. (June 2015).
- Significance: First proposed diffusion models for generation, introducing the core forward (noising) and learned reverse (denoising) processes; foundational for later breakthroughs.
- Anecdote: Initially overlooked by some, partly due to its thermodynamics-focused title seemingly unrelated to mainstream image generation.
- A Lot of GANs… (2015-2021):
- This period saw an explosion of research and improvements in GAN architectures and training techniques. Models like DCGAN, StyleGAN, BigGAN, CycleGAN, etc., pushed the boundaries of image quality, resolution, and controllability, making GANs the dominant approach for state-of-the-art image generation for several years.
- DDPM (2020):
- “Denoising Diffusion Probabilistic Models” by Ho, Jain, and Abbeel (June 2020).
- Significance: A major breakthrough for diffusion models. This paper demonstrated that with specific architectural choices (a U-Net backbone) and training objectives (predicting the added noise), diffusion models could achieve image sample quality competitive with or even superior to leading GANs. It reignited widespread interest in diffusion models.
- DDIM (2020):
- “Denoising Diffusion Implicit Models” by Song, Meng, and Ermon (Oct 2020).
- Significance: Addressed a key limitation of DDPMs: slow sampling due to many required steps. DDIMs introduced a non-Markovian variant of the diffusion process that allowed for much faster generation (fewer sampling steps) without a significant drop in image quality.
- CLIP (2021):
- “Learning Transferable Visual Models From Natural Language Supervision” by Radford et al. (OpenAI, Jan 2021).
- Significance: While not a generative model itself, CLIP learns a shared embedding space for images and text by training on a massive dataset of image-text pairs. Its powerful text encoder became a crucial component for guiding text-to-image generation in models like DALL-E and later Stable Diffusion, enabling much better understanding and execution of complex text prompts.
- Diffusion Beats GANs (2021):
- “Diffusion Models Beat GANs on Image Synthesis” by Dhariwal and Nichol (OpenAI, May 2021).
- Significance: This paper provided strong evidence, through improved architectures and techniques like classifier-free guidance (CFG), that diffusion models could surpass the then state-of-the-art GANs in terms of image quality and distribution coverage for complex datasets like ImageNet. It cemented diffusion models as a leading paradigm.
- Stable Diffusion (2022):
- Based on the “High-Resolution Image Synthesis with Latent Diffusion Models” paper by Rombach, Blattmann, Lorenz, Esser, and Ommer (CompVis LMU, Runway, Stability AI support - Dec 2021, public release Aug 2022).
- Significance: A pivotal open-source release. By applying the diffusion process in a compressed latent space (learned by a VAE) rather than pixel space, Latent Diffusion Models (LDMs) like Stable Diffusion made high-resolution text-to-image generation much more computationally efficient and accessible to the general public. This sparked a massive wave of adoption and community development.
- Diffusion Models (DALL-E, Imagen, etc.) (2021-2025):
- The Diffusion Era (2021-2025): Text-to-Image Dominance
- Significance: Widespread adoption and rapid SOTA advancements in text-to-image generation.
- Key Platforms & Models:
- OpenAI: DALL-E (2021) & DALL-E 2 (2022) showcased impressive capabilities.
- Google: Imagen (2022) achieved SOTA results with cascaded diffusion.
- Midjourney (2022+): Gained immense popularity for its distinct artistic quality.
- RunwayML: Key LDM research contributor & provider of influential generative tools (Gen-1, Gen-2).
- Open Source Surge: Led by Stable Diffusion (LDM, 2022) and its versions (v1.x, SDXL, SD3), plus new architectures like FLUX.1.
- Underlying Advances: Innovations like Flow Matching/Rectified Flow (Lipman, Liu et al.) and Diffusion Transformers (DiT) (Peebles & Xie) further improved training and model capabilities.
- VAR (2024):
- “Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction” by Keyu et al. (April 2024).
- Significance: A novel autoregressive approach that generates images coarse-to-fine (“next-scale prediction”) rather than pixel-by-pixel. Claims to surpass leading diffusion transformers in image quality (FID) and exhibits LLM-like scaling laws. Represents a potential resurgence and new direction for autoregressive models in high-fidelity image generation.
- This paper was published and was awarded the best paper at NeurIPS 2024. However, there are some interesting dramas behind the paper about the author and Bytedance, which is a very interesting story.
- It is specular (but fairly obvious) that 4o (Ghibli), Gemini, etc. used a similar idea for their latest image generation.
It is worth noting that there are a lot of image processing papers that are very interesting, where a subset is SAM, ViT, DINO, etc.
Stable Diffusion
Stable Diffusion is a Latent Diffusion Model (LDM), notable for its open-source nature and wide community adoption, making it an excellent example for understanding modern AI image generation.
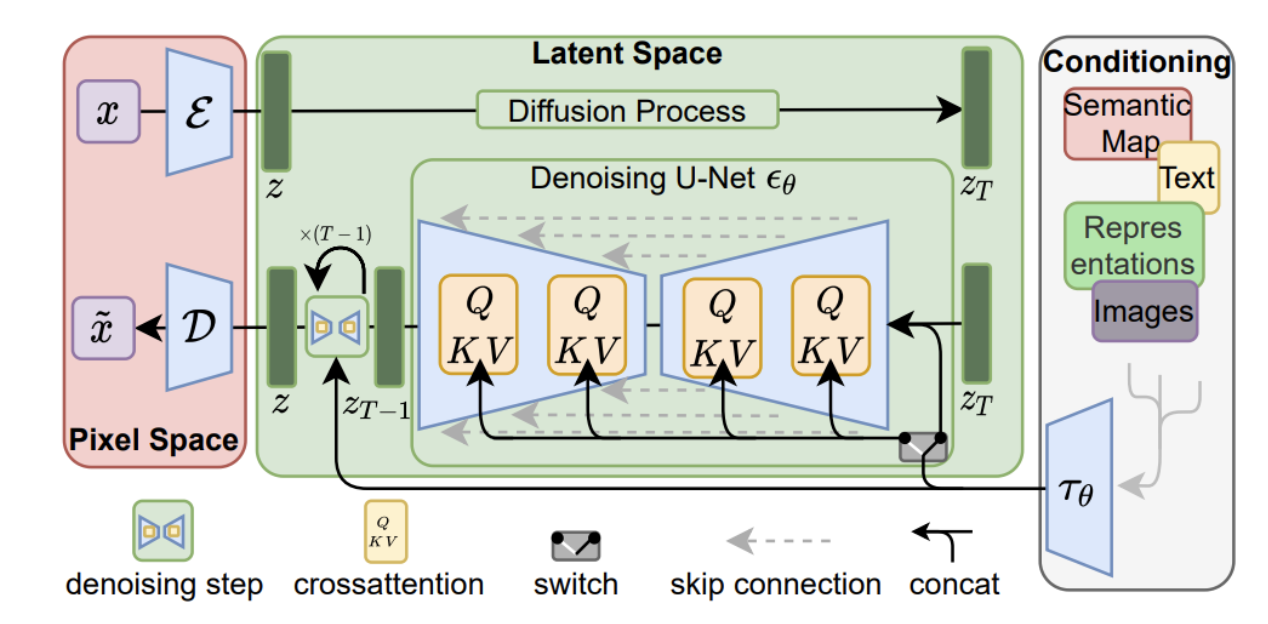
- 1. Encoder & Decoder (VAE): Pixel Space <-> Latent Space
- Encoder (E): Compresses input images into a compact latent representation (z), capturing key visual features. (Used for img2img/training).
- Decoder (D): Reconstructs a full-resolution pixel image from a denoised latent representation (z). This is the final output step.
- For text-to-image, inference starts with noise in latent space, not an initial VAE encode.
- 2. Latent Space Operations: Diffusion & Conditioned Denoising
- Core Idea: Key generative steps (noising, denoising) occur in this efficient, compressed space.
- Forward Diffusion (Training): Clean latents (z) are progressively noised to z_T (pure noise).
- Reverse Denoising (Inference): The U-Net iteratively removes noise from a starting latent (z_T), guided by:
- Text Embeddings (from CLIP/T5 etc., providing semantic guidance via cross-attention).
- Timestep Embeddings (indicating noise level).
- 3. U-Net: The Denoising Engine
- Role: The central neural network that predicts and removes noise from latent z_T to z at each timestep t. Contains most model weights.
- Process: Iteratively refines the latent over ~20-50+ steps (with efficient samplers).
- Architecture: U-shaped encoder-decoder with skip connections and attention mechanisms.
- 4. Classifier-Free Guidance (CFG): Enhancing Prompt Adherence
- Classifier-Free: In traditional image generation, there is usually a classifer involved to guide the generation. However, in Stable Diffusion, there is no classifier. Instead it uses the text embeddings with cross-attention to guide the generation.
- Mechanism: At inference, the U-Net makes two noise predictions per step (one with text prompt, one without). These are combined, amplified by a “CFG scale,” to make the output more strongly follow the prompt.
- Benefit: Improves image-text alignment and image quality without a separate classifier model. Guidance occurs via the U-Net’s understanding of text embeddings (through cross-attention).
- 5. LoRA (Low-Rank Adaptation): Efficient Customization
- Purpose: Fine-tunes pre-trained models for specific styles, characters, or concepts with minimal computation.
- Mechanism: Adds small, trainable “adapter” matrices to frozen U-Net layers (often attention layers).
- Impact: Small file sizes, easy sharing/combination, democratizes model customization.
- 6. ControlNet: Precise Spatial & Structural Control
- Purpose: Adds fine-grained spatial conditioning using an input control image (e.g., pose, depth, edges).
- Mechanism: A trainable copy of U-Net encoder blocks processes a “control map” (from the control image). Its outputs guide the main (locked) U-Net during denoising.
- Impact: Enables precise control over composition, pose, and structure, working alongside text prompts.
Quick Takeaways
The image generation era starts with Variational Autoencoder (VAE), then Generative Adversarial Networks (GANs), then Diffusion Models, and now VAR trends.
So: VAE -> GAN -> Diffusion -> VAR
A classical and open source model is Stable Diffusion.
Stable Diffusion = VAE encode + latent operations (noising, U-net, CFG) + VAE decode