简介
简明扼要地介绍图像生成里程碑的历史至关重要。这个领域可能看起来很嘈杂,有许多关于各种作品取得”好”结果的报道。好消息是,你找到了这篇文章。 虽然不详尽,但它旨在为你提供关键发展背后的强烈直觉,并专注于最新的进展。
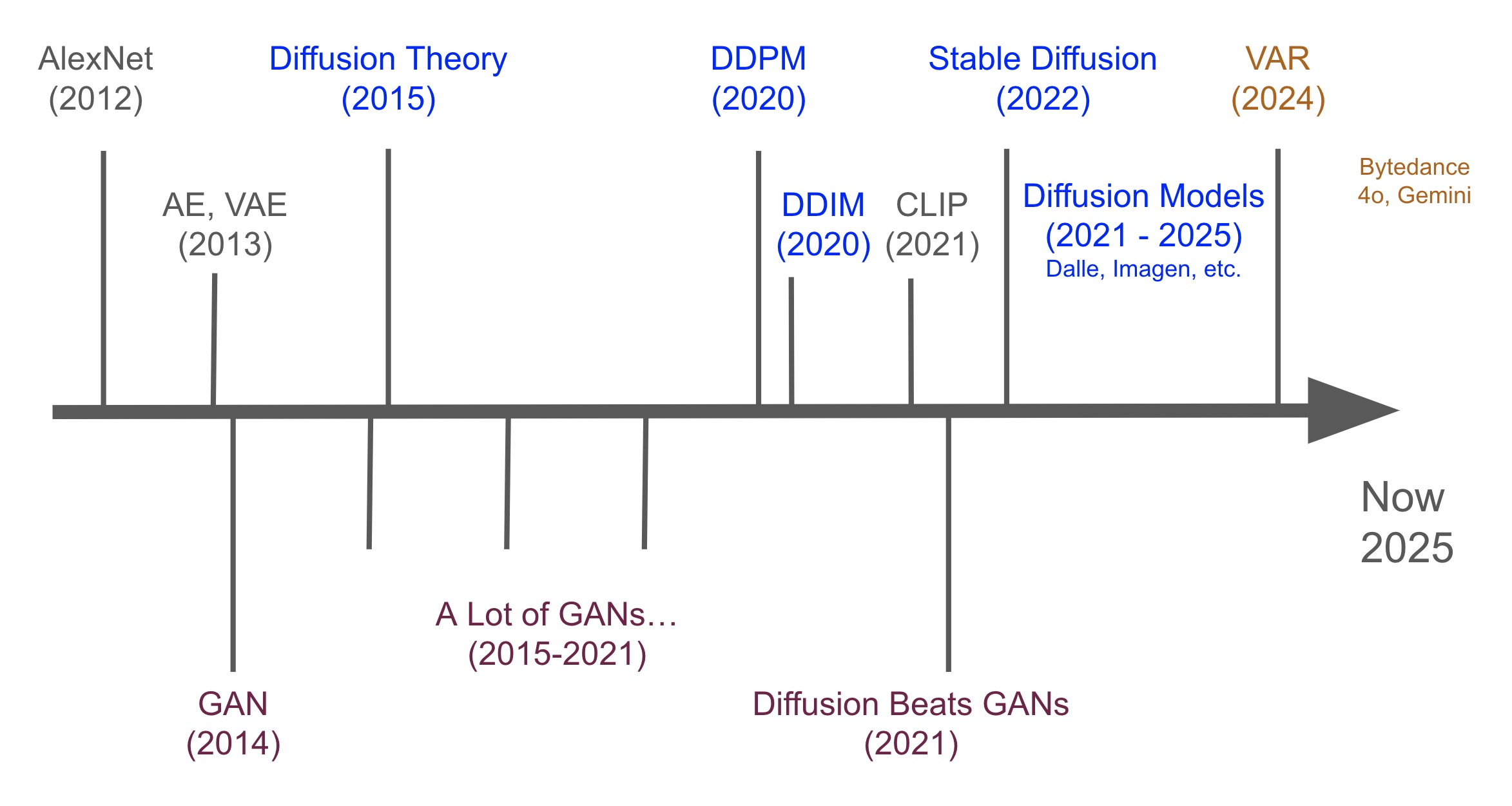
为了简化历史,我们可以将历史分为3个时代:VAE, GAN, Diffusion。 也许还有第4个,VAR 时代,鉴于VAR最近越来越受欢迎。
- AlexNet (2012):
- “Imagenet classification with deep convolutional neural networks” by Krizhevsky, Sutskever, and Hinton.
- 意义: 标志着深度学习时代开始的经典论文。展示了卷积神经网络(CNN)的力量,为其在更复杂的生成模型中的使用铺平了道路。
- Autoencoders (AEs, 自编码器):
- 概念演变了几十年(LeCun, Hinton等人的早期工作)。
- “Reducing the Dimensionality of Data with Neural Networks” by Hinton, G. E. (2006).
- 意义: 一项开创性的工作,引入了自编码器的概念,这是为无监督学习设计的神经网络,主要用于降维或特征学习。
- Variational Autoencoders (VAEs, 变分自编码器):
- “Auto-Encoding Variational Bayes” by Kingma & Welling (Dec 2013)
- “Stochastic Backpropagation and Approximate Inference in Deep Generative Models” by Rezende et al. (Jan 2014).
- 意义: 为学习能够生成新数据的深层潜变量模型提供了一个原则性的概率框架,通过正则化潜空间。
- GAN (2014):
- Generative Adversarial Networks (生成对抗网络): 由Ian Goodfellow等人引入 (June 2014)。
- 意义: 一个突破性的框架,其中两个神经网络,生成器和判别器,相互竞争。生成器试图创建逼真的数据,而判别器试图区分真实数据和生成数据。与VAE等早期方法相比,这种对抗过程导致生成图像的真实感和清晰度显着提高。
- Diffusion Models Theory (扩散模型理论, 2015):
- “Deep Unsupervised Learning using Nonequilibrium Thermodynamics” by Sohl-Dickstein et al. (June 2015).
- 意义: 首次提出用于生成的扩散模型,引入了核心的前向(加噪)和学习的反向(去噪)过程;是后来突破的基础。
- 轶事: 最初被一些人忽视,部分原因是其侧重于热力学的标题似乎与主流图像生成无关。
- A Lot of GANs… (2015-2021):
- 这一时期见证了GAN架构和训练技术的爆炸式研究和改进。像DCGAN, StyleGAN, BigGAN, CycleGAN等模型推动了图像质量、分辨率和可控性的界限,使GAN成为多年来最先进图像生成的主导方法。
- DDPM (2020):
- “Denoising Diffusion Probabilistic Models” by Ho, Jain, and Abbeel (June 2020).
- 意义: 扩散模型的一个重大突破。这篇论文证明,通过特定的架构选择(U-Net主干)和训练目标(预测添加的噪声),扩散模型可以实现与领先的GAN相媲美甚至更优越的图像样本质量。它重新点燃了对扩散模型的广泛兴趣。
- DDIM (2020):
- “Denoising Diffusion Implicit Models” by Song, Meng, and Ermon (Oct 2020).
- 意义: 解决了DDPM的一个关键限制:由于需要许多步骤导致采样缓慢。DDIM引入了扩散过程的非马尔可夫变体,允许更快的生成(更少的采样步骤),而图像质量没有显着下降。
- CLIP (2021):
- “Learning Transferable Visual Models From Natural Language Supervision” by Radford et al. (OpenAI, Jan 2021).
- 意义: 虽然本身不是生成模型,但CLIP通过在海量图像-文本对数据集上进行训练,学习了图像和文本的共享嵌入空间。其强大的文本编码器成为指导DALL-E和后来的Stable Diffusion等模型中文本到图像生成的关键组件,实现了对复杂文本提示的更好理解和执行。
- Diffusion Beats GANs (2021):
- “Diffusion Models Beat GANs on Image Synthesis” by Dhariwal and Nichol (OpenAI, May 2021).
- 意义: 这篇论文通过改进的架构和技术(如无分类器指导 CFG),提供了强有力的证据,证明扩散模型在复杂数据集(如ImageNet)的图像质量和分布覆盖方面可以超过当时最先进的GAN。它巩固了扩散模型作为领先范式的地位。
- Stable Diffusion (2022):
- 基于 “High-Resolution Image Synthesis with Latent Diffusion Models” 论文 by Rombach, Blattmann, Lorenz, Esser, and Ommer (CompVis LMU, Runway, Stability AI support - Dec 2021, public release Aug 2022).
- 意义: 一个关键的开源发布。通过在压缩的潜空间(由VAE学习)而不是像素空间中应用扩散过程,像Stable Diffusion这样的潜在扩散模型(LDM)使高分辨率文本到图像生成在计算上更加高效,并且对公众更加可及。这引发了大规模的采用和社区开发浪潮。
- Diffusion Models (DALL-E, Imagen, etc.) (2021-2025):
- 扩散时代 (2021-2025): 文本到图像的主导地位
- 意义: 广泛采用和文本到图像生成的快速SOTA进步。
- 关键平台与模型:
- OpenAI: DALL-E (2021) & DALL-E 2 (2022) 展示了令人印象深刻的能力。
- Google: Imagen (2022) 通过级联扩散实现了SOTA结果。
- Midjourney (2022+): 因其独特的艺术质量而获得了巨大的人气。
- RunwayML: 关键的LDM研究贡献者和有影响力的生成工具(Gen-1, Gen-2)提供商。
- 开源激增: 由 Stable Diffusion (LDM, 2022) 及其版本 (v1.x, SDXL, SD3) 以及像 FLUX.1 这样的新架构引领。
- 底层进步: 像 Flow Matching/Rectified Flow (Lipman, Liu et al.) 和 Diffusion Transformers (DiT) (Peebles & Xie) 这样的创新进一步改进了训练和模型能力。
- VAR (2024):
- “Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction” by Keyu et al. (April 2024).
- 意义: 一种新颖的自回归方法,从粗到细(”下一尺度预测”)生成图像,而不是逐像素生成。声称在图像质量(FID)上超过了领先的扩散Transformer,并展示了类似LLM的缩放定律。代表了自回归模型在高保真图像生成中潜在的复兴和新方向。
- 这篇论文发表并获得了 NeurIPS 2024最佳论文奖。然而,关于作者和字节跳动,论文背后有一些有趣的戏剧性事件,这是一个非常有趣的故事。
- 推测(但相当明显)4o (Ghibli), Gemini等在其最新的图像生成中使用了类似的想法。
值得注意的是,有许多非常有趣的图像处理论文,其中一个子集是SAM, ViT, DINO等。
Stable Diffusion
Stable Diffusion是一个潜在扩散模型(LDM),以其开源性质和广泛的社区采用而闻名,使其成为理解现代AI图像生成的绝佳示例。
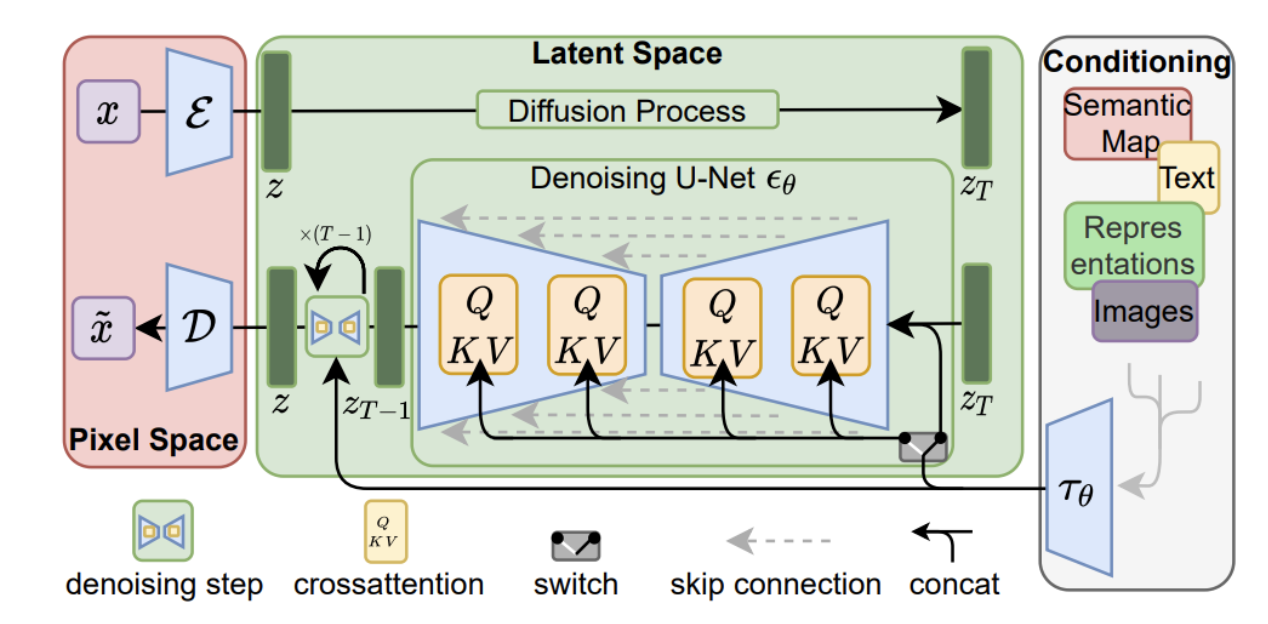
- 1. Encoder & Decoder (VAE): 像素空间 <-> 潜空间
- Encoder (E): 将输入图像压缩成紧凑的潜在表示 (z),捕获关键视觉特征。(用于img2img/训练)。
- Decoder (D): 从去噪的潜在表示 (z) 重建全分辨率像素图像。这是最后的输出步骤。
- 对于文本到图像,推理从潜空间中的噪声开始,而不是初始VAE编码。
- 2. Latent Space Operations: 扩散与条件去噪
- 核心思想: 关键生成步骤(加噪,去噪)发生在这个高效、压缩的空间中。
- 前向扩散 (训练): 干净的潜变量 (z) 逐渐加噪成为 z_T (纯噪声)。
- 反向去噪 (推理): U-Net 迭代地从起始潜变量 (z_T) 去除噪声,指导因素包括:
- 文本嵌入 (来自CLIP/T5等,通过交叉注意力提供语义指导)。
- 时间步嵌入 (指示噪声水平)。
- 3. U-Net: 去噪引擎
- 角色: 预测并在每个时间步 t 从潜变量 z_T 去除噪声到 z 的核心神经网络。包含大多数模型权重。
- 过程: 在约20-50+步内迭代细化潜变量(使用高效采样器)。
- 架构: 具有跳跃连接和注意力机制的U形编码器-解码器。
- 4. Classifier-Free Guidance (CFG): 增强提示词依从性
- 无分类器: 在传统图像生成中,通常涉及分类器来指导生成。然而,在Stable Diffusion中,没有分类器。相反,它使用带有交叉注意力的文本嵌入来指导生成。
- 机制: 在推理时,U-Net每步进行两次噪声预测(一次有文本提示,一次没有)。这些被组合,并由”CFG scale”放大,使输出更强烈地遵循提示。
- 好处: 提高图像-文本对齐和图像质量,无需单独的分类器模型。指导通过U-Net对文本嵌入的理解(通过交叉注意力)发生。
- 5. LoRA (Low-Rank Adaptation): 高效定制
- 目的: 以最小的计算量微调预训练模型,用于特定风格、角色或概念。
- 机制: 向冻结的U-Net层(通常是注意力层)添加小的、可训练的”适配器”矩阵。
- 影响: 文件小,易于分享/组合,使模型定制民主化。
- 6. ControlNet: 精确的空间与结构控制
- 目的: 使用输入控制图像(例如,姿势,深度,边缘)添加细粒度的空间条件。
- 机制: U-Net编码器块的可训练副本处理”控制图”(来自控制图像)。其输出在去噪期间指导主(锁定)U-Net。
- 影响: 实现对构图、姿势和结构的精确控制,与文本提示一起工作。
快速要点
图像生成时代始于变分自编码器 (VAE),然后是生成对抗网络 (GAN),然后是扩散模型 (Diffusion Models),现在是VAR趋势。
所以:VAE -> GAN -> Diffusion -> VAR
一个经典且开源的模型是Stable Diffusion。
Stable Diffusion = VAE encode + latent operations (noising, U-net, CFG) + VAE decode