I spent 100 hours to build an vector (embedding) search engine from ground up, and I ended up learning much more. I want to share what I learned, to save you some time when you need to go through a similar journey. I summarized my understanding into a brief history, and then the basic and fundamental concepts, and then share the best engineering suggestions and practices I learned.
TL;DR:
- I classify the search into 3 levels: keyword search, embedding search, and agentic search.
- I built a embedding search (semantic search engine) from ground up in 100 hours, with the goal of searching products. Keyword search can not satisfy our need for search a product using a description, where we need sematic matching (e.g., cloth vs shirt), and even multimodal information (product images, etc.).
- Embedding, a vector representation of objects (users, products, etc.), is essentially just a list of numbers, e.g., [0.37, 0.2, 0.48, 0.4], which condenses the information of objects (a.k.a. reduce the dimensionality of the object description). So we can use distance to measure the similarity between objects. It can be understood as a more efficient way than the old “one-hot” encoding.
- Embedding is the backbone of LLM (e.g., word2vec). It is also the foundation of recommendation and ranking systems (basically a user embedding + item embedding -> similarity score).
- While LLM can deal with negative prompts, object embedding still can NOT deal with negative prompts yet, e.g., “not red” will be much closer to “red” than “blue”.
- Serializing structured data into a unified string format improves accuracy, whereas embedding raw JSON syntax hurts performance.
- My recommendated stack: PostgresSQL (traditional database) + Qwen (text embedding, and optionally reranker) + CLIP (multimodal embedding) + pgvector (vector database) + HNSW (approximate nearest neighbor algorithm) + optionally your search software for multiple rounds (hybrid elastic search, RAG, agentic search, etc.).
- More details in the following sections.
Brief History of Embedding
I divide the history of embedding into 3 phases: keyword search (index, frequncy, inverted index), semantic search (embedding, vector database, approximate nearest neighbor algorithm), which clearly lead to hybrid search / RAG (Retrieval-Augmented Generation) / Agentic search (multi-round with LLMs).
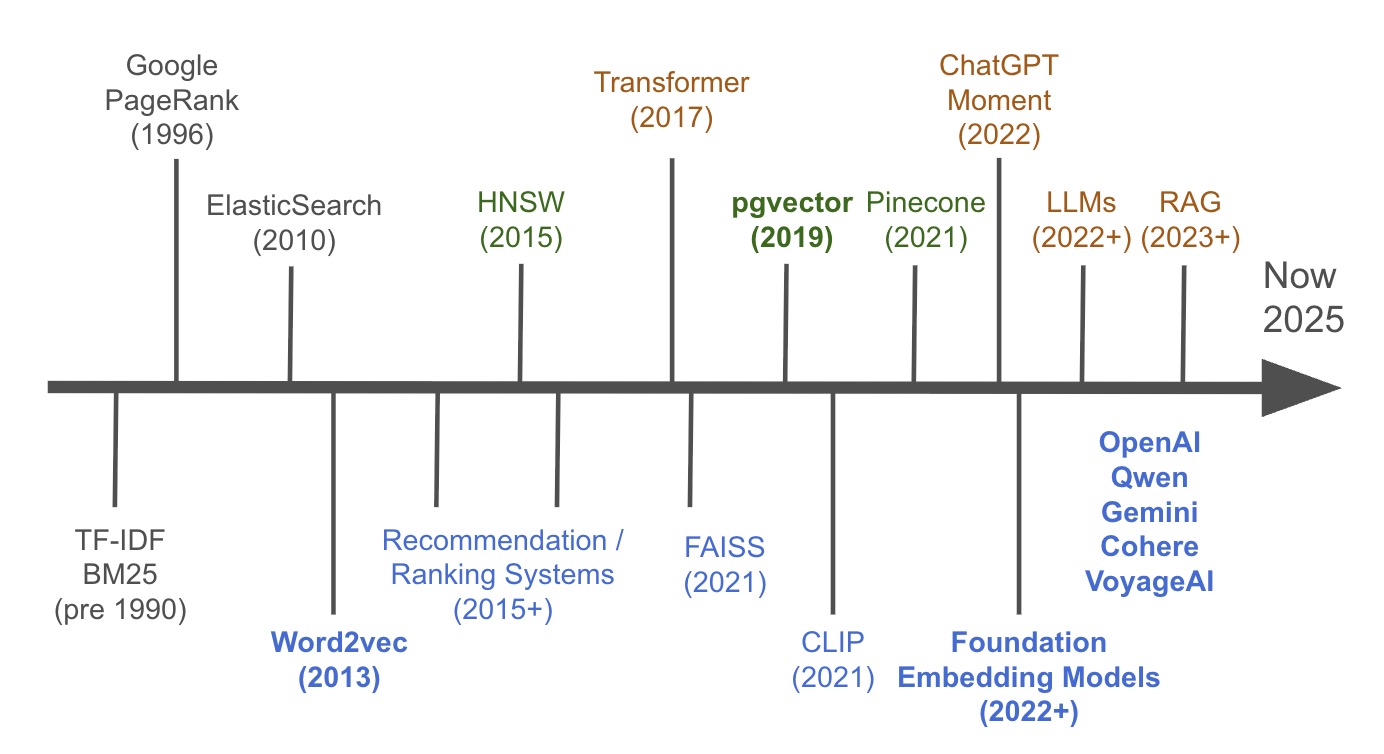
The key milestones are:
Pre-1990: Term Frequency-Inverse Document Frequency (TF-IDF) & BM25
- Foundational statistical methods that enabled search engines to rank documents based on keyword frequency and relevance, forming the bedrock of lexical search. Kd-tree is another keyword you should know if you are interested in this topic.
1996: Google PageRank
-
A revolutionary algorithm that determined a webpage’s importance by analyzing the quantity and quality of links pointing to it, fundamentally changing web search.
-
Page, L., Brin, S., et al. (1998). The Anatomy of a Large-Scale Hypertextual Web Search Engine.
2010: Elasticsearch
- A distributed search and analytics engine that made scalable, real-time full-text search widely accessible to developers. The Elasticsearch Project site.
2013: Word2vec
-
A groundbreaking model that learned to represent words as numerical vectors, capturing their semantic relationships and enabling machines to understand context.
-
Mikolov, T., et al. (2013). Efficient Estimation of Word Representations in Vector Space.
2015: HNSW (Hierarchical Navigable Small Worlds)
-
A highly efficient algorithm for approximate nearest neighbor search, making it practical to find similar items in massive vector datasets almost instantly.
2017: Transformer
-
A novel neural network architecture based on a self-attention mechanism, which became the foundational technology for nearly all modern large language models. Probably also need to mention BERT.
- Vaswani, A., et al. (2017). Attention Is All You Need.
- Devlin, J., et al. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
2017: FAISS (Facebook AI Similarity Search)
-
A core library developed by Meta (Facebook) AI providing highly optimized algorithms for efficient similarity search and clustering of dense vectors.
-
Johnson, J., Douze, M., & Jégou, H. (2017). Billion-scale similarity search with GPUs.
2019: pgvector
-
An open-source extension for the PostgreSQL database that added vector similarity search, allowing developers to combine traditional and semantic search in one system.
2021: Pinecone
-
Established in 2019 and get public attention in 2021, Pinecone is a fully managed, cloud-native vector database designed for high-performance, large-scale similarity search in production applications. Basically a market leader for vector database, although everyone has basically caught up.
2021: CLIP (Contrastive Language–Image Pre-training)
-
A multi-modal model from OpenAI that connects images and text by learning from their natural language descriptions, enabling powerful cross-modal search. There is an open source version which is more or less still the state-of-the-art for image embedding (LAION-5B bigG).
- Radford, A., et al. (2021). Learning Transferable Visual Models From Natural Language Supervision.
- LAION’s ViT-bigG CLIP. downloaded 2 million times.
2022: ChatGPT Moment
-
The public release of ChatGPT, which made advanced AI accessible to millions and triggered a massive wave of development in generative AI.
2022+: Foundation Embedding Models & LLMs
- The rapid advancement and proliferation of massive neural networks and specialized models (e.g., from OpenAI, Cohere) for generating text and creating high-quality vector embeddings.
2023+: RAG (Retrieval-Augmented Generation)
-
While proposed in 2020, RAG became popular in 2023 with the release of GPT-3.5 and GPT-4. It is a powerful architecture that enhances LLMs by first retrieving relevant data from an external knowledge base (like a vector database) to generate more accurate answers.
-
Lewis, P., et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.
Basic Concepts
What is embedding?
- A vector representation of objects (users, products, etc.).
- It is essentially just a list of numbers, e.g., [0.37, 0.2, 0.48, 0.4].
- It basically condenses the information of objects (a.k.a. reduce the dimensionality of the object description), so we can use distance to measure the similarity between objects. It is a more efficient way than the old “one-hot” encoding.
- It is the backbone of LLM (e.g., word2vec). It is also the foundation of recommendation and ranking systems (basically a user embedding + item embedding -> similarity score).
- While LLM can deal with negative prompts, object embedding still can NOT deal with negative prompts, e.g., “not red” will be much closer to “red” than “blue”.
Cosine similarity vs Euclidean distance (L2 norm)
- Cosine similarity is a measure of similarity between two vectors, which is the cosine of the angle between them.
- Euclidean distance is a measure of similarity between two vectors, which is the square root of the sum of the squared differences between the two vectors.
- Cosine similarity is more sensitive to the angle between the two vectors, while Euclidean distance is more sensitive to the magnitude of the two vectors.
- Default to cosine similarity for embedding search.
Model Selection
- Qwen 3 is king, open source with good size selections. They also provide you a reranker model, which gives you a pairwise score if your need accuracy.
all-mpnet-base-v2was the old king, but not anymore.- OpenAI is still a good option, and a default option for a lot of developers because of their early adoption.
- Cohere is the startup market leader for embedding models. There is a story of Nils Reimers, who was the author of the sentence-transformer, joined Hugging Face, and then Cohere. If I name 3 most influential people in the embedding space, Nils Reimers will be one of them, together with Gerard Salton in the 1970s for the concept of vector space model (VSM) and word2vec first author Tomas Mikolov.
- VoyageAI is another good option, which is acquired by MongoDB (2 years into 200 million) and I happen to know the CEO Tengyu Ma, a Stanford professor.
- Gemini released an embedding model July 2025, which has been in experimentation since March 2025. They had terrible documentation which confused me but here is the verified (July 2025) way to use it. Also you can deploy your own embedding models using Vertex AI.
- MTEB embedding leaderboard is your best friend.
- For multimodal embedding, you can use CLIP, sigCLIP, specifically, I recommend LAION-5B bigG.
A classic Two-Stage Retrieval Process: Recall + Rerank
Vector search is fast but approximate. For maximum accuracy, use two stages.
-
Recall (Fast): Use your vector database to quickly fetch a large set of candidates (e.g., the top 100). This stage is for speed and broad coverage.
-
Rerank (Accurate): Use a slower, more powerful reranker model on that small set of 100 candidates. It re-sorts them with high precision for the final result. While Qwen provides a great reranker, other classic and powerful options are worth knowing. The underlying technology is typically a cross-encoder, which processes the query and a document together for much higher accuracy than embedding similarity alone, e.g., ms-marco Models, Cohere Rerank, BERT Cross-Encoders, etc. This should give you most of the accuracy you need. If you are at a stage that 0.1% matters, you should hire a expert :-)
This gives you the best of both worlds: speed across the whole dataset and high accuracy on the results you show. You can even add another middle layer, pre-rank, which is basically a simpler version of reranker.
Evaluation
Metrics tell you if your search is actually good.
-
Precision@k: Of your top K results, how many are relevant? Measures the quality of what you show.
-
Recall@k: Of all possible relevant items, how many did you find in your top K? Measures what you’re missing.
-
Mean Reciprocal Rank (MRR): What’s the rank of the first correct answer? Best for Q&A or when one right answer is needed.
-
Normalized Discounted Cumulative Gain (nDCG): The gold standard. Rewards highly relevant results at the top of the list.
Vector Databases
You need a vector database because a for loop to check every item is too slow. They use Approximate Nearest Neighbor (ANN) algorithms like HNSW to make search near-instant.
-
Integrated (pgvector): Your recommended choice. Combines vectors and traditional SQL filters in one database. Simple and powerful.
-
Dedicated (Pinecone, Milvus, Qdrant): Standalone databases built for extreme scale and performance. Adds complexity but is faster for massive datasets.
To build applications on top of these databases faster, many developers use additional tools. Platforms like Supabase provide a managed pgvector setup out of the box. Frameworks like LlamaIndex or LangChain offer libraries to orchestrate the entire RAG pipeline (chunking, retrieval, etc.), which saves you from writing a lot of boilerplate code.
Chunking
I didn’t encounter this issue, but it is common if you have a really big file.
- The key idea is don’t embed huge documents, where vector becomes a useless, blurry average of too many topics.
- The goal is to break large text into smaller, semantically focused chunks before embedding.
- Strategy: Start with recursive character splitting (splits by paragraph, then sentence). It’s a smart default.
- Pro tip: Use chunk overlap (e.g., a few sentences) to maintain context between chunks.
Future of search
The future is Agentic Search.
It’s not a single lookup. An AI agent deconstructs a complex query (“waterproof jacket under $150 with good reviews”) into a multi-step plan. This plan can involve multiple vector searches, SQL filters, and even searching within the reviews of initial results. Finally, the agent synthesizes the findings into a single, reasoned answer.
Search is evolving from a lookup tool into a research assistant.