我花了100个小时从零开始构建了一个向量(嵌入)搜索引擎,结果我学到了更多。我想分享我学到的东西,以便在你需要经历类似旅程时为你节省一些时间。我将我的理解总结为 简史,然后是 基本和基础概念,然后分享我学到的 最佳工程建议和实践。
太长不看版 (TL;DR):
- 我将搜索分为 3个级别:关键词搜索,嵌入搜索,和 代理搜索。
- 我在100小时内从零构建了一个 嵌入搜索(语义搜索引擎),目标是搜索产品。关键词搜索无法满足我们使用描述搜索产品的需求,我们需要 语义匹配(例如,布 vs 衬衫),甚至 多模态信息(产品图片等)。
- 嵌入,对象的向量表示(用户、产品等),本质上只是 一串数字,例如 [0.37, 0.2, 0.48, 0.4],它 浓缩了对象的信息(即降低对象描述的维度)。所以我们可以使用 距离来衡量对象之间的相似度。可以将其理解为比旧的”one-hot”编码更有效的方式。
- 嵌入是 LLM的骨干(例如,word2vec)。它也是推荐和排名系统的基础(基本上是用户嵌入 + 物品嵌入 -> 相似度分数)。
- 虽然LLM可以处理负面提示,但对象嵌入仍然 还不能处理负面提示,例如,”不是红色”会比”蓝色”更接近”红色”。
- 将结构化数据序列化为 统一的字符串 格式可以提高准确性,而嵌入原始JSON语法会损害性能。
- 我推荐的技术栈:PostgresSQL(传统数据库)+ Qwen(文本嵌入,和可选的重排序器)+ CLIP(多模态嵌入)+ pgvector(向量数据库)+ HNSW(近似最近邻算法)+ 可选的用于多轮搜索的软件(混合弹性搜索,RAG,代理搜索等)。
- 更多细节在以下部分。
嵌入简史
我将嵌入的历史分为3个阶段:关键词搜索(索引,频率,倒排索引),语义搜索(嵌入,向量数据库,近似最近邻算法),这清楚地导向 混合搜索 / RAG (检索增强生成) / 代理搜索 (与LLM的多轮对话)。
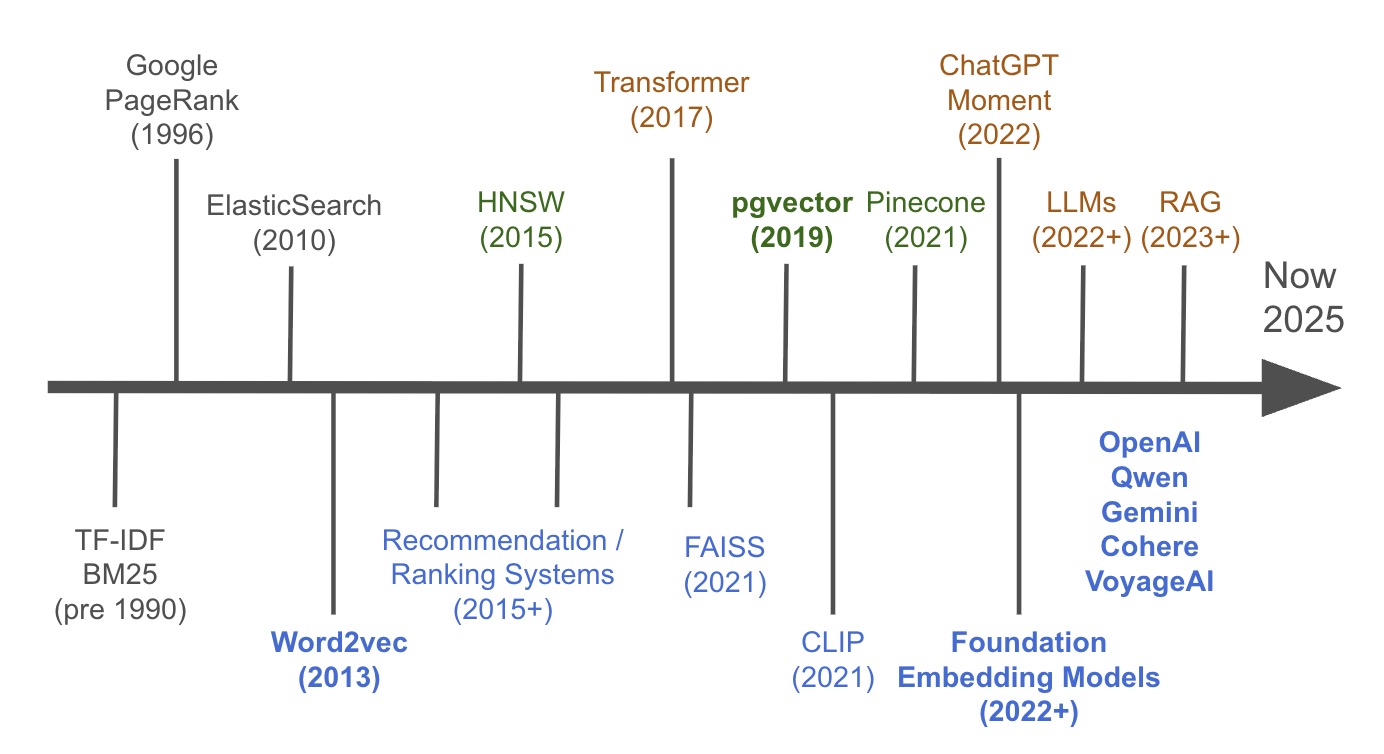
关键里程碑是:
Pre-1990: Term Frequency-Inverse Document Frequency (TF-IDF) & BM25
- 基础统计方法,使搜索引擎能够根据关键词频率和相关性对文档进行排名,构成了词汇搜索的基石。如果你对这个话题感兴趣,Kd-tree是你应该知道的另一个关键词。
1996: Google PageRank
-
一种革命性的算法,通过分析指向网页的链接的数量和质量来确定网页的重要性,从根本上改变了网络搜索。
-
Page, L., Brin, S., et al. (1998). The Anatomy of a Large-Scale Hypertextual Web Search Engine.
2010: Elasticsearch
- 一个分布式搜索和分析引擎,使开发者能够广泛使用可扩展的、实时的全文搜索。The Elasticsearch Project site.
2013: Word2vec
-
一个突破性的模型,学会了将单词表示为数值向量,捕获它们的语义关系并使机器能够理解上下文。
-
Mikolov, T., et al. (2013). Efficient Estimation of Word Representations in Vector Space.
2015: HNSW (Hierarchical Navigable Small Worlds)
-
一种高效的近似最近邻搜索算法,使得在海量向量数据集中几乎瞬间找到相似项成为可能。
2017: Transformer
-
一种基于自注意力机制的新型神经网络架构,成为几乎所有现代大型语言模型的基础技术。可能还需要提到BERT。
- Vaswani, A., et al. (2017). Attention Is All You Need.
- Devlin, J., et al. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
2017: FAISS (Facebook AI Similarity Search)
-
Meta (Facebook) AI开发的核心库,为密集向量的高效相似性搜索和聚类提供高度优化的算法。
-
Johnson, J., Douze, M., & Jégou, H. (2017). Billion-scale similarity search with GPUs.
2019: pgvector
-
PostgreSQL数据库的开源扩展,添加了向量相似性搜索,允许开发者在一个系统中结合传统搜索和语义搜索。
2021: Pinecone
-
成立于2019年并在2021年获得公众关注,Pinecone是一个完全托管的云原生向量数据库,专为生产应用中的高性能、大规模相似性搜索而设计。基本上是向量数据库的市场领导者,尽管每个人都基本上赶上了。
2021: CLIP (Contrastive Language–Image Pre-training)
-
OpenAI的多模态模型,通过从自然语言描述中学习来连接图像和文本,实现强大的跨模态搜索。有一个开源版本,或多或少 仍然是图像嵌入的最先进技术 (LAION-5B bigG)。
- Radford, A., et al. (2021). Learning Transferable Visual Models From Natural Language Supervision.
- LAION’s ViT-bigG CLIP. downloaded 2 million times.
2022: ChatGPT Moment
-
ChatGPT的公开发布,使数以百万计的人可以使用先进的AI,并引发了生成式AI的大规模发展浪潮。
2022+: Foundation Embedding Models & LLMs
- 大规模神经网络和专用模型(例如,来自OpenAI, Cohere)的快速进步和扩散,用于生成文本和创建高质量的向量嵌入。
2023+: RAG (Retrieval-Augmented Generation)
-
虽然在2020年提出,但RAG随着GPT-3.5和GPT-4的发布在2023年变得流行。它是一种强大的架构,通过首先从外部知识库(如向量数据库)检索相关数据来增强LLM,以生成更准确的答案。
-
Lewis, P., et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.
基本概念
什么是嵌入?
- 对象的向量表示(用户、产品等)。
- 它本质上只是一串数字,例如 [0.37, 0.2, 0.48, 0.4]。
- 它基本上浓缩了对象的信息(即降低对象描述的维度),所以我们可以使用距离来 衡量对象之间的相似度。这是一种比旧的”one-hot”编码更有效的方式。
- 它是 LLM的骨干(例如,word2vec)。它也是推荐和排名系统的基础(基本上是用户嵌入 + 物品嵌入 -> 相似度分数)。
- 虽然LLM可以处理负面提示,但对象嵌入仍然还不能处理负面提示,例如,”不是红色”会比”蓝色”更接近”红色”。
余弦相似度 (Cosine similarity) vs 欧几里得距离 (Euclidean distance, L2 norm)
- 余弦相似度是两个向量之间相似性的度量,是它们之间夹角的余弦。
- 欧几里得距离是两个向量之间相似性的度量,是两个向量之间平方差之和的平方根。
- 余弦相似度对两个向量之间的角度更敏感,而欧几里得距离对两个向量的大小更敏感。
- 嵌入搜索默认使用 余弦相似度。
模型选择
- Qwen 3 是王道,开源且有好的尺寸选择。他们还提供了一个 reranker model,如果你需要准确性,它会给你一个成对的分数。
all-mpnet-base-v2是旧王,但现在不是了。- OpenAI仍然是一个不错的选择,也是许多开发者的默认选择,因为他们早期采用。
- Cohere是嵌入模型的创业市场领导者。有一个关于 Nils Reimers 的故事,他是sentence-transformer的作者,加入了Hugging Face,然后是Cohere。如果我列举嵌入领域最有影响力的3个人,Nils Reimers将是其中之一,还有1970年代提出 向量空间模型 (VSM) 概念的 Gerard Salton 和 word2vec 第一作者 Tomas Mikolov。
- VoyageAI是另一个不错的选择,被MongoDB收购(2年2亿),我碰巧认识CEO Tengyu Ma,一位斯坦福教授。
- Gemini在2025年7月发布了一个 嵌入模型,自2025年3月以来一直在实验中。他们的文档很糟糕,让我很困惑,但这里是 验证过的(2025年7月)使用方法。你也可以使用Vertex AI部署你自己的嵌入模型。
- MTEB embedding leaderboard 是你最好的朋友。
- 对于多模态嵌入,你可以使用CLIP, sigCLIP,具体来说,我推荐 LAION-5B bigG。
经典的双阶段检索过程:召回 + 重排序
向量搜索很快但是近似的。为了最大准确性,使用两个阶段。
-
召回 (Recall, 快):使用你的向量数据库快速获取一大组候选者(例如,前100个)。这个阶段是为了速度和广泛覆盖。
-
重排序 (Rerank, 准):在那一小部分100个候选者上使用更慢、更强大的重排序模型。它以高精度重新排序它们以获得最终结果。虽然Qwen提供了一个很棒的重排序器,但其他经典和强大的选项也值得了解。底层技术通常是交叉编码器(cross-encoder),它一起处理查询和文档,比单独的嵌入相似度准确得多,例如 ms-marco Models, Cohere Rerank, BERT Cross-Encoders 等。这应该给你所需的大部分准确性。如果你处于0.1%都很重要的阶段,你应该雇佣一个专家 :-)
这给了你两全其美:整个数据集的速度和显示结果的高准确性。你甚至可以添加另一个中间层,预排序(pre-rank),这基本上是重排序器的简化版本。
评估
指标告诉你你的搜索是否真的好。
-
Precision@k: 在你的前K个结果中,有多少是相关的?衡量你展示内容的质量。
-
Recall@k: 在所有可能的相关项中,你在前K个中找到了多少?衡量你遗漏了什么。
-
Mean Reciprocal Rank (MRR): 第一个正确答案的排名是多少?最适合问答或需要一个正确答案时。
-
Normalized Discounted Cumulative Gain (nDCG): 黄金标准。奖励列表顶部的相关性高的结果。
向量数据库
你需要一个向量数据库,因为for循环检查每一项太慢了。它们使用近似最近邻(ANN)算法,如HNSW,使搜索几乎即时。
-
集成 (pgvector):你的推荐选择。在一个数据库中结合向量和传统SQL过滤器。简单而强大。
-
专用 (Pinecone, Milvus, Qdrant):为极端规模和性能构建的独立数据库。增加了复杂性,但对于海量数据集更快。
为了更快地在这些数据库之上构建应用程序,许多开发者使用额外的工具。像 Supabase 这样的平台提供了开箱即用的托管pgvector设置。像 LlamaIndex 或 LangChain 这样的框架提供了库来编排整个RAG管道(分块,检索等),这为你节省了编写大量样板代码的时间。
分块 (Chunking)
我没有遇到这个问题,但如果你有一个非常大的文件,这很常见。
- 关键思想是 不要嵌入巨大的文档,那样向量会变成太多主题的无用、模糊的平均值。
- 目标是 在嵌入之前将大文本分解为更小的、语义集中的块。
- 策略:从递归字符分割开始(按段落分割,然后按句子)。这是一个明智的默认值。
- 专业提示:使用 块重叠(例如,几句话)来保持块之间的上下文。
搜索的未来
未来是 代理搜索 (Agentic Search)。
它不是单一的查找。一个AI代理将复杂的查询(”150美元以下好评的防水夹克”)分解为一个多步骤计划。这个计划可以涉及多个向量搜索,SQL过滤器,甚至在初始结果的评论中搜索。最后,代理将发现合成为一个单一的、经过推理的答案。
搜索正在从查找工具演变为研究助手。