The Problem
The whole point is trying to explain how to fit a 400B model into GPUs.
Preface
In college, if you sign up for a course named “Introduction to xxx”, you know you are in trouble. You need to spend days and nights on that course. Those include “introduction to algorithms”, which no one knows how to solve the practice problems; “introduction to computer systems”, which brings you C and assembly languages; not to mention the braindead “introduction abstract algebra” or “introduction to compilers”. While hard and time consuming, if you master those “introductory” courses, you usually have a good start and the learning curve will be much smoother.
The good news is, you find this article.
This will give you a solid foundational understanding of the parallelism in LLM training. Luckily, for most people, including some researchers and engineers working closely to the AI world, would not need more knowledge than what is covered in this article. The intuition behind things are most important.
Overview
Data parallelism
If you have a small model, you can fit into one GPU - great. Assume you want to train faster - say use 4 GPUs. You can just have one copy (replica) in each GPU, and let each of them learn separately and sync what they have learned. This is what is called “Data parallelism”. This is probably the most straightward thing people come up with naturally. They are other improvements, e.g., ZeRO, which can futher save your GPU memory.
Model parallelism
Things get tricky when your model gets larger. For example, a 70B model (e.g., QwQ 70B) with FP8 (float point with 8 bits) would easily exceed 150GBs of memory. Obviously, one GPU (even H100 with 80GB) is not enough. You need to think about ways to cut the model.
Recall we are training neural networks, which consists of layers. My other article Visualizing Generation in LLM gives a good intuition of layers and tensors. One thing to come up naturally is to cut by layers (e.g., GPU 1 has layer 1-10, GPU 2 has layer 11-20). This is improved by using “Pipeline Parallelism”.
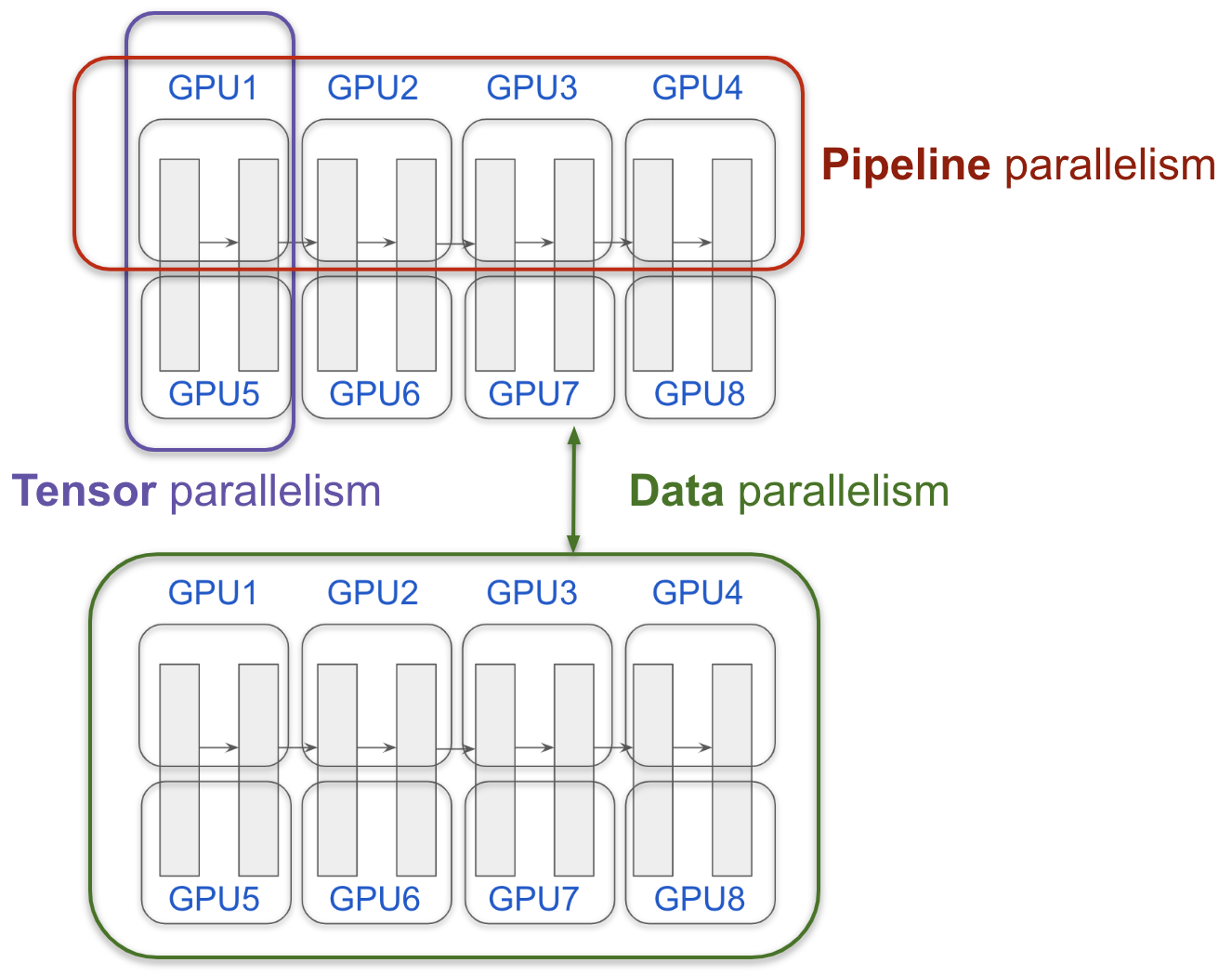
There is another technique called “tensor parallelism” that cuts each layer, which you can imagine needs some good engineering. Above graph shows the idea of cutting by layers and cutting by tensor.
For Mixture of Experts (MoEs) e.g., Switch Transformer and DeepSeek V3, you can obviously cut by experts (e.g., each GPU has 4 experts). This is called “Expert parallelism”.
Those are essentially it. This naturally explains what Nvidia is doing and why NVlink helps, and explains why XAI built a “200k” GPU cluster, and very soon Grok-3 became the State of the Art (SOTA) on the most popular benchmark.
The full story
Hugging Face just released a ultralarge model training playbook which you will easily lose interest if you don’t know what you are looking for.
CS336 assignment2 provides another good practice to code parallelism.
But those are “advanced courses”. Let’s just focus on Parallelism 101.
In this article, I will essentially introduce 4 papers, AlexNet, GPipe, Megatron, and MoE.
Before we started, I’d like to introduce the alchemy part of LLM training: unlike theoretical research, this is experimental science. People try things and come up with the theory later.
AlexNet
By January 2025, the Alexnet paper Imagenet classification with deep convolutional neural networks (2012) has been cited 172,000 times in Google Scholar. It was groundbreaking in deep learning, demonstrating the power of convolutional neural networks (CNNs) at scale and revolutionizing computer vision. The model’s superior performance in the ImageNet competition marked the beginning of the deep learning era, inspiring a wave of advancements in AI.
A key challenge in training AlexNet was GPU memory constraints — the model was too large to fit on a single GPU available at the time (NVIDIA GTX 580 with 3GB memory). To overcome this, model parallelism was introduced, where the network was split across two GPUs. One GPU handled half of the model’s filters in each convolutional layer, while the other GPU processed the remaining half. Communication between GPUs occurred only at certain layers, minimizing overhead while leveraging the combined memory and computational power of both GPUs.
This approach paved the way for large-scale deep learning, demonstrating that computational constraints could be overcome through parallelization techniques, an idea that remains fundamental in training today’s massive neural networks.
Ilya Sutskever
I’d like to introduce Ilya Sutskever a bit more, who has been a central figure in modern AI — not just as a co-founder of OpenAI but as a researcher whose contributions span the foundational breakthroughs of deep learning. His name appears as a co-author on some of the most influential papers, including:
- AlexNet – Ignited the deep learning revolution in computer vision. 172,000+ citations.
- Dropout – A widely used regularization technique to prevent overfitting. 50,000+ citations.
- Sequence to Sequence Learning – Laid the groundwork for modern transformer models. 28,000+ citations.
- AlphaGo – The first AI system to defeat human champions in Go. Nature, and I gues I don’t need to introduce AlphaGo.
- TensorFlow The tensor flow paper. 58,000+ citations.
Unlike many modern AI papers with dozens of co-authors, many of Ilya’s early works had just a few key contributors, underscoring his deep, hands-on involvement. His research has not only shaped the trajectory of AI but has also enabled the large-scale training of neural networks that power today’s models.
It’s no surprise that Geoffrey Hinton has spoken so highly of him—not just for his groundbreaking research, but also as he once said:
“I’m particularly proud of the fact that one of my students fired Sam Altman”
Youtube link — right before receiving the Nobel Prize in Physics.
Another fun fact is that the three authors formed a company DNNresearch and was acquired by Google soon. After realizing the importance of GPUs, Google started to build TPU.
Data Parallelism
I think it’s still important to illustrate Data Parallelism — a natural yet crucial technique in distributed deep learning.
How Data Parallelism Works
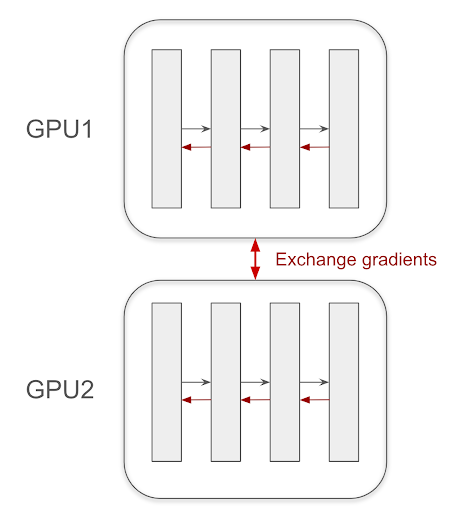
In Data Parallelism, each GPU holds a complete copy of the model, referred to as a replica. When processing a batch of data, the batch is split across GPUs, with each GPU independently computing forward and backward passes on its assigned subset. Once gradients are computed, they are averaged and synchronized across all GPUs before updating the model’s weights.
Why Data Parallelism Matters
Before the Transformer era, Data Parallelism was particularly efficient, as most models still fit within the memory of a single GPU. It allowed training to scale efficiently across multiple GPUs without requiring major changes to the model itself.
With the rise of Transformers and larger architectures, Data Parallelism alone is no longer sufficient due to memory constraints. Instead, it is often combined with Model Parallelism and Pipeline Parallelism to handle the growing size of models.
ZeRO and Beyond
I won’t dive into ZeRO (Zero Redundancy Optimizer), which further optimizes memory usage by reducing the redundancy of model weights across replicas. However, the key idea is to reduce memory overhead in Data Parallelism while keeping its scalability benefits.
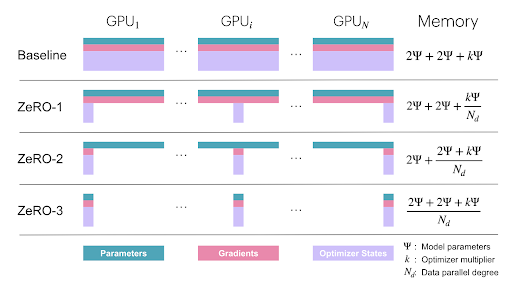
For a deeper dive into memory-efficient training, check out the ZeRO paper: 🔗 ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
As models continue to scale, data parallelism alone is not enough.
Pipeline Parallelism
It is natural to split the model by layers, which introduces some inefficiencies that most of the time GPUs are idle.
Now, let’s talk about GPipe, another foundational work from Google that significantly advanced efficient model training using Pipeline Parallelism.
I had the opportunity to work with Yanping Huang, the first author, during my time at Google. He was promoted fast🚀. The last two authors, Yonghui Wu (who recently joined TikTok) and Zhifeng Chen, are also key figures in deep learning research and influential contributors to large-scale model training.
How GPipe Works: Micro-Batching & Reducing “Bubble” Time
A typical Google paper is known for its well-crafted figures, and GPipe is no exception. See below image for illustrating the key idea. One of its key contributions is the introduction of micro-batching, which significantly reduces “bubble” time in pipeline parallelism.
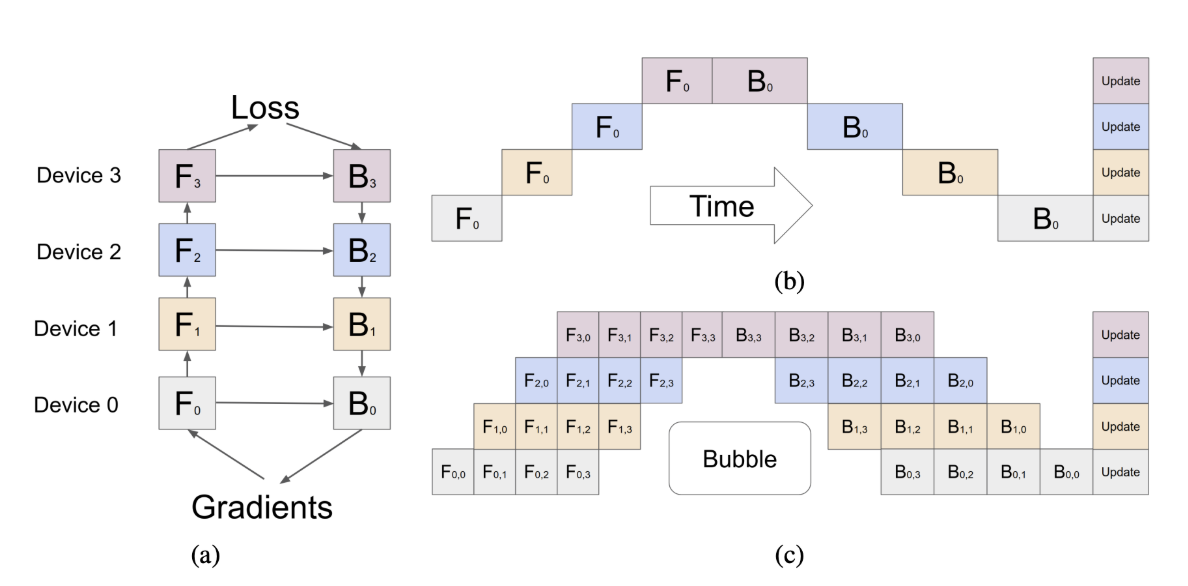
What is “Bubble” Time?
In Pipeline Parallelism, large models are split into multiple stages, each running on a separate GPU. However, when training starts, some GPUs remain idle while waiting for the previous stages to complete their computations. This idle period, known as “bubble” time, leads to inefficient hardware utilization.
How Micro-Batching Fixes This Issue
GPipe introduces micro-batching, where a large batch is split into smaller micro-batches that are sequentially processed through the pipeline. This allows different stages of the model to start working on new micro-batches before the previous ones have fully completed, significantly reducing idle time.
🔹 Key Benefits of Micro-Batching in GPipe:
- Minimizes bubble time, keeping all GPUs engaged and reducing wasted computation.
- Improves memory efficiency, making it possible to train larger models.
- Enhances parallelism, leading to better hardware utilization and faster training convergence.
By breaking the model into pipeline stages and processing smaller chunks of data simultaneously, GPipe achieves a smooth training flow, ensuring that no GPU sits idle for long. This idea remains critical in scaling modern deep learning models.
For a deeper dive, check out the GPipe paper: 🔗 GPipe: Efficient Training of Giant Neural Networks Using Pipeline Parallelism
Question Time! 🎯
For a LayerNorm, does it normalize on the global batch or the micro-batch?
💡 Answer: It normalizes on the micro-batch! Since micro-batching alters how data is fed into the pipeline, normalization is performed within each micro-batch, rather than across the entire original batch. This ensures that statistics like mean and variance are computed locally for each micro-batch, maintaining consistency throughout training.
Tensor Parallelism
By 2019, researchers working on large language models (LLMs) primarily focused on model parallelism by layers — dividing models vertically across GPUs, where each GPU handled a different set of layers.
However, an alternative approach had been explored: cutting the model in a different direction. While earlier attempts struggled with efficiency and complexity, it wasn’t until Megatron-LM that “non-intrusive” tensor parallelism produced significant improvements.
From Layer Splitting to Tensor Parallelism
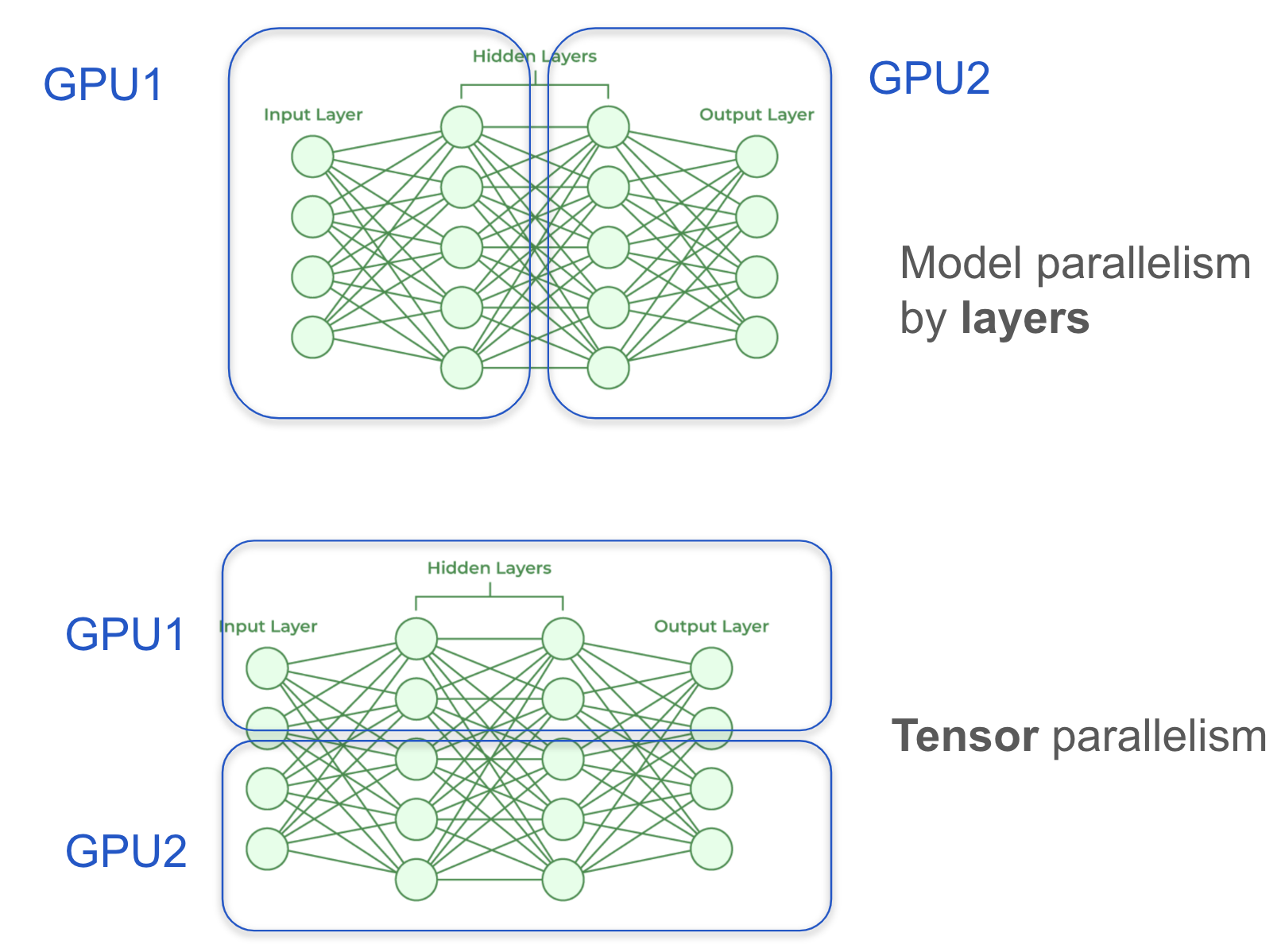
- Layer-wise model parallelism (top diagram): Each GPU is responsible for a subset of layers, sequentially passing activations to the next GPU.
- Tensor parallelism (bottom diagram): Instead of cutting the model by layers, it is split horizontally within each layer. Each GPU handles part of the same layer’s computations, reducing memory overhead while enabling efficient parallel execution.
Key Challenges & Innovations
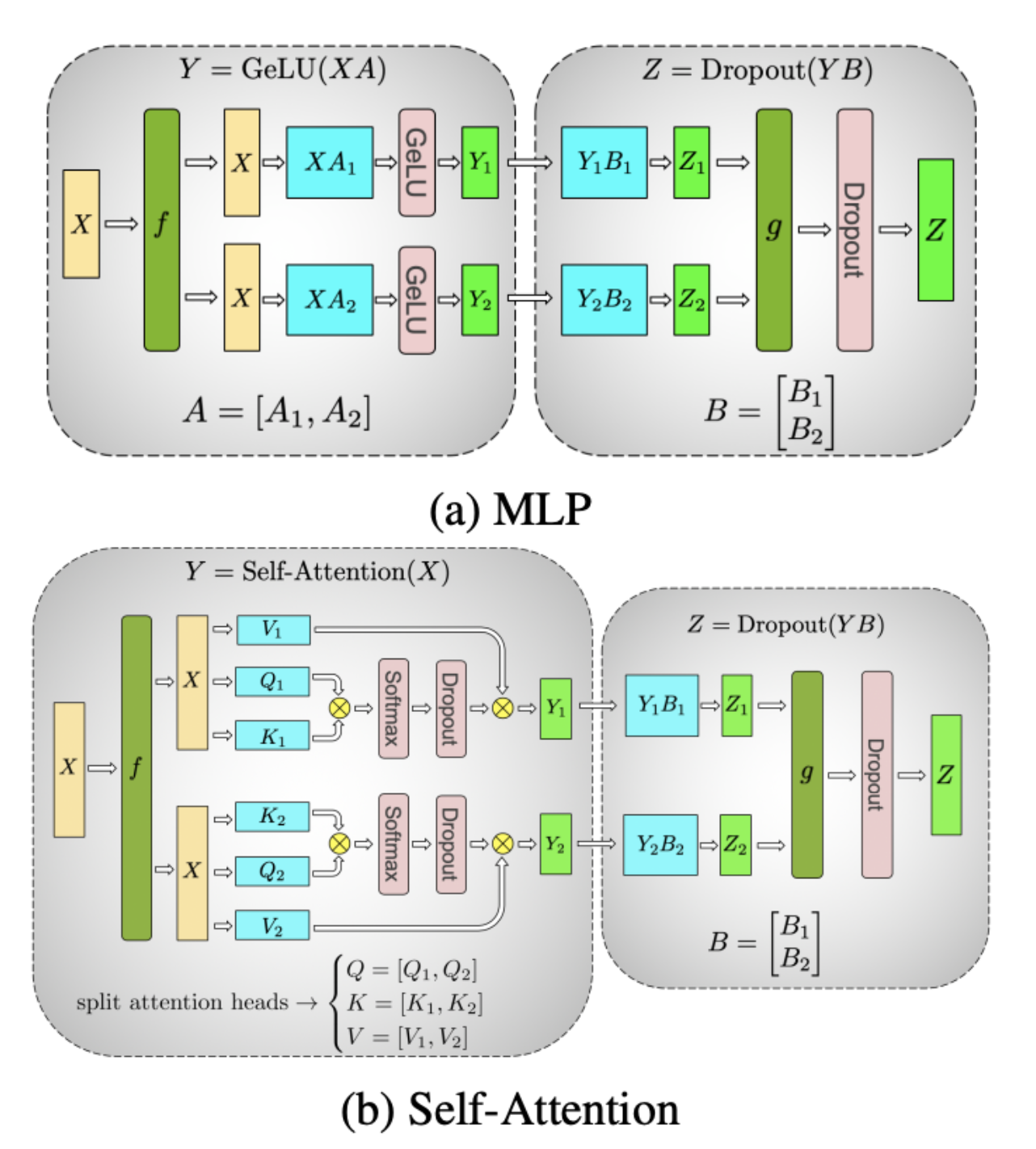
- Shared Computation: Some components, like embeddings and layer normalization, must remain synchronized across GPUs to maintain consistency.
- High-Speed Interconnects: NVLink, NVIDIA’s high-bandwidth GPU interconnect, is essential for fast communication between GPUs in tensor parallelism.
Megatron’s tensor parallelism paved the way for scaling models beyond a single GPU’s memory limits, a crucial advancement for training GPT-3 and beyond. Today, hybrid parallelism (combining tensor, pipeline, and data parallelism) is the standard for training massive neural networks efficiently.
For a deeper dive, check out the Megatron paper: 🔗 Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Expert Parallelism
I wasn’t originally planning to discuss Expert Parallelism (EP), but with DeepSeek open-sourcing DeepEP, it’s worth revisiting.
Origins of Expert Parallelism
Expert Parallelism (EP) originates from the Switch Transformer paper (2021), which introduced Mixture of Experts (MoE) scaling for deep learning models. This approach enables efficient trillion-parameter models by activating only a subset of “expert” layers per forward pass, significantly reducing computational costs. Some fun facts:
- First & second authors: William Fedus and Barret Zoph both went to OpenAI. Given their MoE expertise, the rumor of GPT-4o leveraging MoE seems quite reasonable.
- Last author: Noam Shazeer, a co-inventor of the Transformer, later founded Character.AI. Interestingly, Google recently acquired Character.AI, bringing him back into the Google ecosystem.
DeepEP from DeepSeek
DeepSeek’s DeepEP is now open-sourced during the Deepseek open sour week, bringing high-performance MoE-style expert parallelism to the community.
Recall that Deepseek V3 has
- 256 experts, with top-8 experts selected per token.
- This setup is vastly different from Mistral’s MoE (8 experts total).
- In DeepEP, each individual expert is relatively shallow, but the system’s expert routing allows for a much higher total expert count while maintaining inference efficiency.
- A reasonable estimate is each GPU handles ~1-4 experts.
Also, note that each token is generated from 8 experts. But we can tell silicon experts collaborate better than carbon experts, huah? 🤖🔥
Future reading
Top resources
Hugging Face: ultralarge model training playbook
Checkout the “Finding the Best Training Configuration” section for a practical guide.
Hugging Face Picotron: Minimalistic 4D-parallelism distributed training framework for education purpose
Stanford CS336 assignment2: distributed data parallel training
Relevant Papers
Alexnet, GPipe, Megatron, Switch Transformer have been introduced above.
I used to list some, but it’s not a good idea.
Ask LLM (active learning is much more effective).
Ending
Hugging Face article provide a good summary of what you should use given the model size and the number of GPUs.
I don’t think it’s practical to memorize these details, and more importantly, I don’t think you should. Developing an intuition is sufficient.
I’d like to highlight again that this is experimental science - another dimension of the alchemy for training LLM. You won’t know what generates the highest throughput until you experiment.
Let’s review together and make sure you take something home: