问题
重点在于解释如何将一个 400B的模型放入GPU。
前言
在大学里,如果你报名了一门名为 “xxx入门” 的课程,你知道你有麻烦了。你需要在这门课上花费日日夜夜。这些包括 “算法导论”,没人知道怎么解决练习题;“计算机系统导论”,它带给你C语言和汇编语言;更不用说令人头大的 “抽象代数导论” 或 “编译器导论”。虽然很难且耗时,但如果你掌握了这些”入门”课程,你通常会有一个好的开始,学习曲线会平滑得多。
好消息是,你找到了这篇文章。
这将为你提供LLM训练中并行性的坚实基础理解。幸运的是,对于大多数人,包括一些与AI世界紧密合作的研究人员和工程师,不需要比本文涵盖的更多的知识。背后的直觉是最重要的。
概览
数据并行 (Data parallelism)
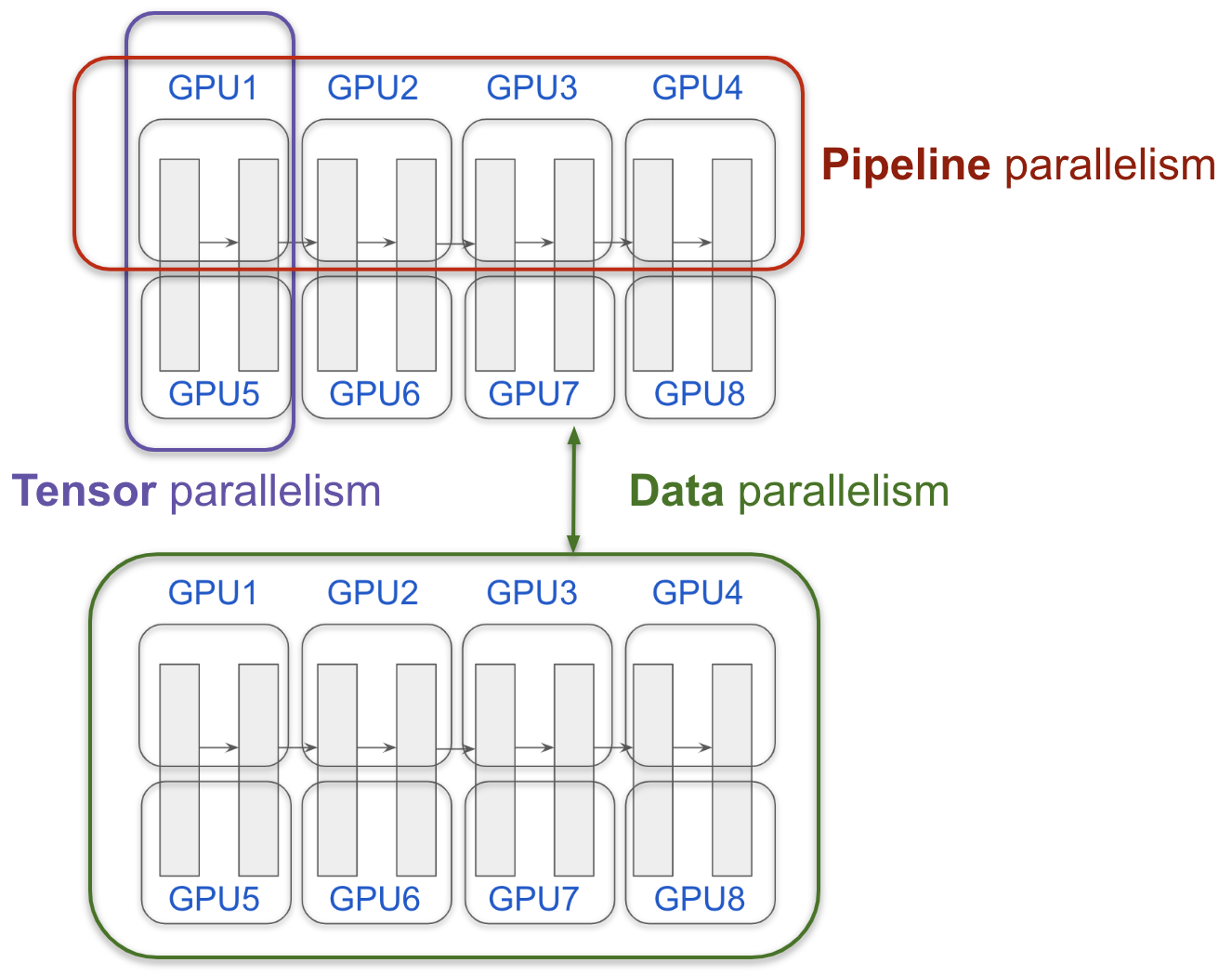
如果你有一个小模型,你可以放入一个GPU - 很好。假设你想训练得更快 - 比如使用4个GPU。你可以只在每个GPU中有一个副本(replica),让它们分别学习并同步它们学到的东西。这就是所谓的 “数据并行”。这可能是人们自然想到的最直接的事情。还有其他改进,例如 ZeRO,它可以进一步节省你的GPU内存。
模型并行 (Model parallelism)
当你的模型变大时,事情变得棘手。例如,一个 70B模型(例如 QwQ 70B)使用FP8(8位浮点数)将轻易超过150GB的内存。显然,一个GPU(即使是具有80GB的H100)是不够的。你需要考虑 切割模型 的方法。
回顾一下我们正在训练神经网络,它由层组成。我的另一篇文章 可视化LLM生成过程 给出了层和张量的良好直觉。自然想到的一件事是按层切割(例如,GPU 1有层1-10,GPU 2有层11-20)。这通过使用 “流水线并行 (Pipeline Parallelism)” 得到改进。
还有一种称为 “张量并行 (tensor parallelism)” 的技术,它切割每一层,你可以想象这需要一些好的工程。上面的图展示了 按层切割 和 按张量切割 的想法。
对于混合专家(MoE),例如 Switch Transformer 和 DeepSeek V3,你显然可以按专家切割(例如,每个GPU有4个专家)。这被称为 “专家并行 (Expert parallelism)”。
基本上就是这些。这自然解释了Nvidia在做什么以及为什么NVlink有帮助,并解释了为什么XAI建立了一个”200k” GPU集群,并且很快Grok-3成为了最受欢迎基准测试的SOTA。
完整故事
Hugging Face刚刚发布了一个 超大模型训练手册,如果你不知道你在找什么,你很容易失去兴趣。
CS336 assignment2 提供了另一个编写并行代码的好练习。
但这都是 “高级课程”。让我们只关注 并行性101。
在这篇文章中,我将主要介绍4篇论文,AlexNet, GPipe, Megatron, 和 MoE。
在我们开始之前,我想介绍一下LLM训练的炼金术部分:与理论研究不同,这是 实验科学。人们尝试事物,后来才提出理论。
AlexNet
到2025年1月,Alexnet论文 Imagenet classification with deep convolutional neural networks (2012) 在Google Scholar上已被引用 172,000次。它在深度学习方面具有开创性,展示了大规模卷积神经网络(CNN)的力量,并彻底改变了计算机视觉。该模型在ImageNet竞赛中的优越表现标志着深度学习时代的开始,激发了AI进步的浪潮。
训练AlexNet的一个关键挑战是 GPU内存限制 — 模型太大,无法放入当时可用的单个GPU(具有3GB内存的NVIDIA GTX 580)。为了克服这个问题,引入了 模型并行,网络被拆分到两个GPU上。一个GPU处理每个卷积层中一半的过滤器,而另一个GPU处理剩下的一半。GPU之间的通信仅在某些层发生,在利用两个GPU的组合内存和计算能力的同时最小化开销。
这种方法为大规模深度学习铺平了道路,证明了可以通过并行化技术克服计算限制,这一想法在今天训练大规模神经网络中仍然是基础。
Ilya Sutskever
我想多介绍一点 Ilya Sutskever,他一直是现代AI的核心人物 — 不仅作为OpenAI的联合创始人,而且作为一名研究人员,其贡献跨越了 深度学习的基础突破。他的名字作为合著者出现在一些最有影响力的 论文 中,包括:
- AlexNet – 点燃了计算机视觉的深度学习革命。172,000+ 引用。
- Dropout – 一种广泛使用的正则化技术,防止过拟合。50,000+ 引用。
- Sequence to Sequence Learning – 为现代transformer模型奠定了基础。28,000+ 引用。
- AlphaGo – 第一个在围棋中击败人类冠军的AI系统。Nature,我想我不需要介绍AlphaGo。
- TensorFlow TensorFlow论文。58,000+ 引用。
与许多拥有 数十名合著者 的现代AI论文不同,Ilya的许多早期作品只有几个主要贡献者,强调了他 深入的亲身参与。他的研究不仅 塑造了AI的轨迹,而且使 大规模训练 神经网络成为可能,从而为今天的模型提供动力。
难怪 Geoffrey Hinton 对他评价如此之高——不仅因为他的 开创性研究,还因为他曾经说过:
“我特别自豪的一件事是,我的一个学生解雇了Sam Altman”
Youtube链接 — 就在获得 诺贝尔物理学奖 之前。
另一个有趣的事实是,这三位作者成立了一家公司DNNresearch,并很快被Google收购。在意识到GPU的重要性后,Google开始构建 TPU。
数据并行 (Data Parallelism)
我认为说明 数据并行 仍然很重要 — 这是分布式深度学习中一种自然且 至关重要 的技术。
数据并行如何工作
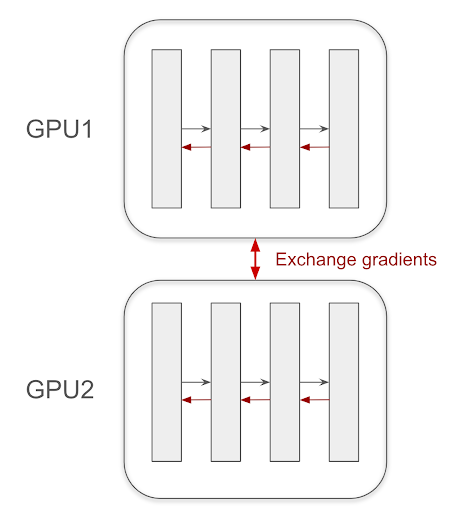
在 数据并行 中,每个 GPU持有模型的完整副本,称为 副本(replica)。当处理一批数据时,该批次被 拆分到GPU,每个GPU独立计算其分配子集的 前向和后向传递。一旦计算出梯度,它们将在更新模型权重之前在所有GPU上进行 平均和同步。
为什么数据并行很重要
在 Transformer时代 之前,数据并行特别 高效,因为大多数模型仍然 适合单个GPU的内存。它允许训练在多个GPU上有效地扩展,而无需对模型本身进行重大更改。
随着 Transformer和更大架构 的兴起,由于内存限制,仅靠数据并行已不再足够。相反,它通常 与模型并行和流水线并行结合使用 来处理不断增长的模型大小。
ZeRO及以后
我不会深入探讨 ZeRO (Zero Redundancy Optimizer),它通过减少副本间模型权重的冗余来进一步 优化内存使用。然而,关键思想是在保持其可扩展性优势的同时 减少数据并行中的内存开销。
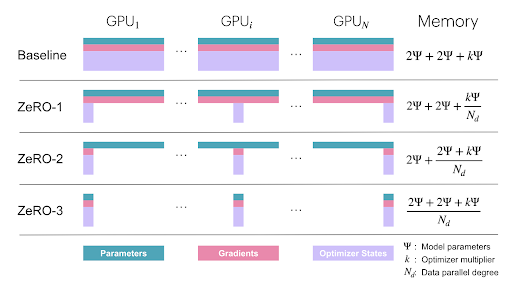
要深入了解内存高效训练,请查看 ZeRO论文: 🔗 ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
随着模型继续扩展,仅靠 数据并行 是不够的。
流水线并行 (Pipeline Parallelism)
按层拆分模型是很自然的,这引入了一些低效,因为大多数时候GPU是空闲的。
现在,让我们谈谈 GPipe,这是Google的另一项 基础工作,它使用 流水线并行 显着推进了 高效模型训练。
我有机会在Google期间与第一作者 Yanping Huang 一起工作。他晋升很快🚀。最后两位作者 Yonghui Wu(最近加入TikTok)和 Zhifeng Chen 也是深度学习研究的 关键人物 和大规模模型训练的 有影响力的贡献者。
GPipe如何工作:微批处理(Micro-Batching)与减少”气泡”(Bubble)时间
典型的 Google论文 以其 精心制作的图表 而闻名,GPipe也不例外。见下图说明关键思想。其 关键贡献 之一是引入了 微批处理,这显着 减少了流水线并行中的”气泡”时间。
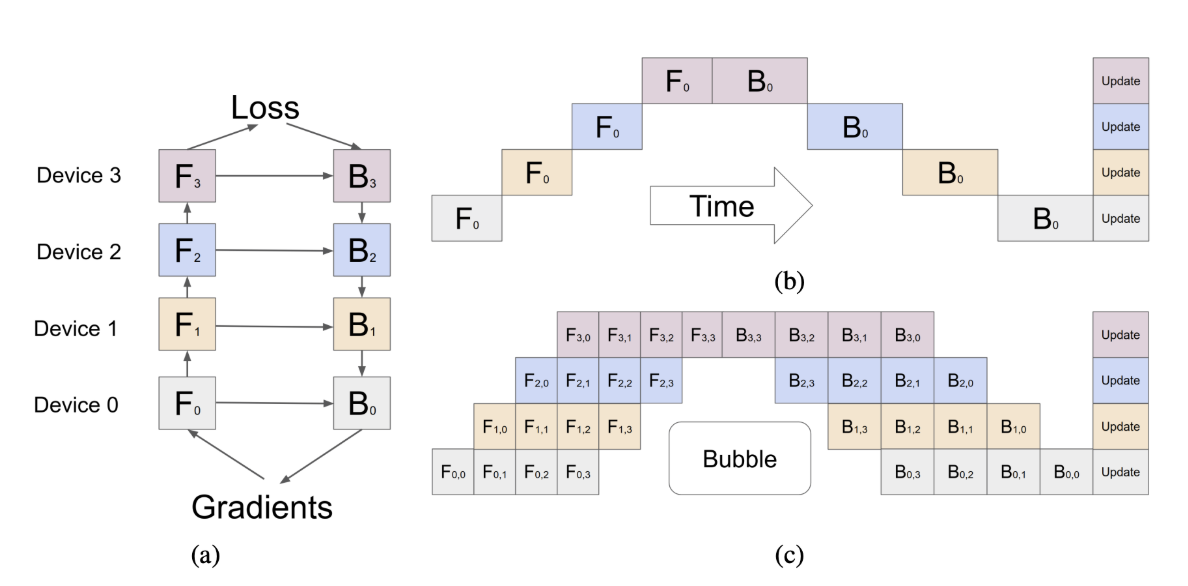
什么是”气泡”时间?
在 流水线并行 中,大型模型被 拆分为多个阶段,每个阶段在单独的GPU上运行。然而,当训练开始时,一些GPU保持 空闲,等待前一阶段完成其计算。这个 空闲期,称为 “气泡”时间,导致硬件利用率低。
微批处理如何解决这个问题
GPipe引入了 微批处理,其中大批次被 拆分为较小的微批次,这些微批次通过流水线顺序处理。这允许模型的不同阶段在 前一个微批次完全完成之前开始处理新的微批次,显着 减少空闲时间。
🔹 GPipe中微批处理的主要好处:
- 最小化气泡时间,保持所有GPU参与并减少浪费的计算。
- 提高内存效率,使训练 更大的模型 成为可能。
- 增强并行性,导致 更好的硬件利用率 和 更快的训练收敛。
通过 将模型分解为流水线阶段 并 同时处理较小的数据块,GPipe实现了 平滑的训练流程,确保 没有GPU长时间闲置。这个想法在 扩展现代深度学习模型 中仍然至关重要。
要深入了解,请查看GPipe论文:🔗 GPipe: Efficient Training of Giant Neural Networks Using Pipeline Parallelism
提问时间! 🎯
对于 LayerNorm,它是在 全局批次 还是 微批次 上进行归一化?
💡 答案: 它在微批次上进行归一化! 由于微批处理改变了数据输入流水线的方式,归一化是在 每个微批次内 执行的,而不是在整个原始批次上。这确保了像 均值和方差 这样的统计数据是为每个微批次局部计算的,在整个训练过程中保持一致性。
张量并行 (Tensor Parallelism)
到 2019年,致力于 大型语言模型 (LLM) 的研究人员主要关注 按层的模型并行 — 将模型 垂直 划分到GPU上,其中每个GPU处理不同的一组层。
然而,已经探索了另一种方法:在不同方向上切割模型。虽然早期的尝试在效率和复杂性方面挣扎,但直到 Megatron-LM,“非侵入式”张量并行 才产生了 显着的改进。
从层分割到张量并行
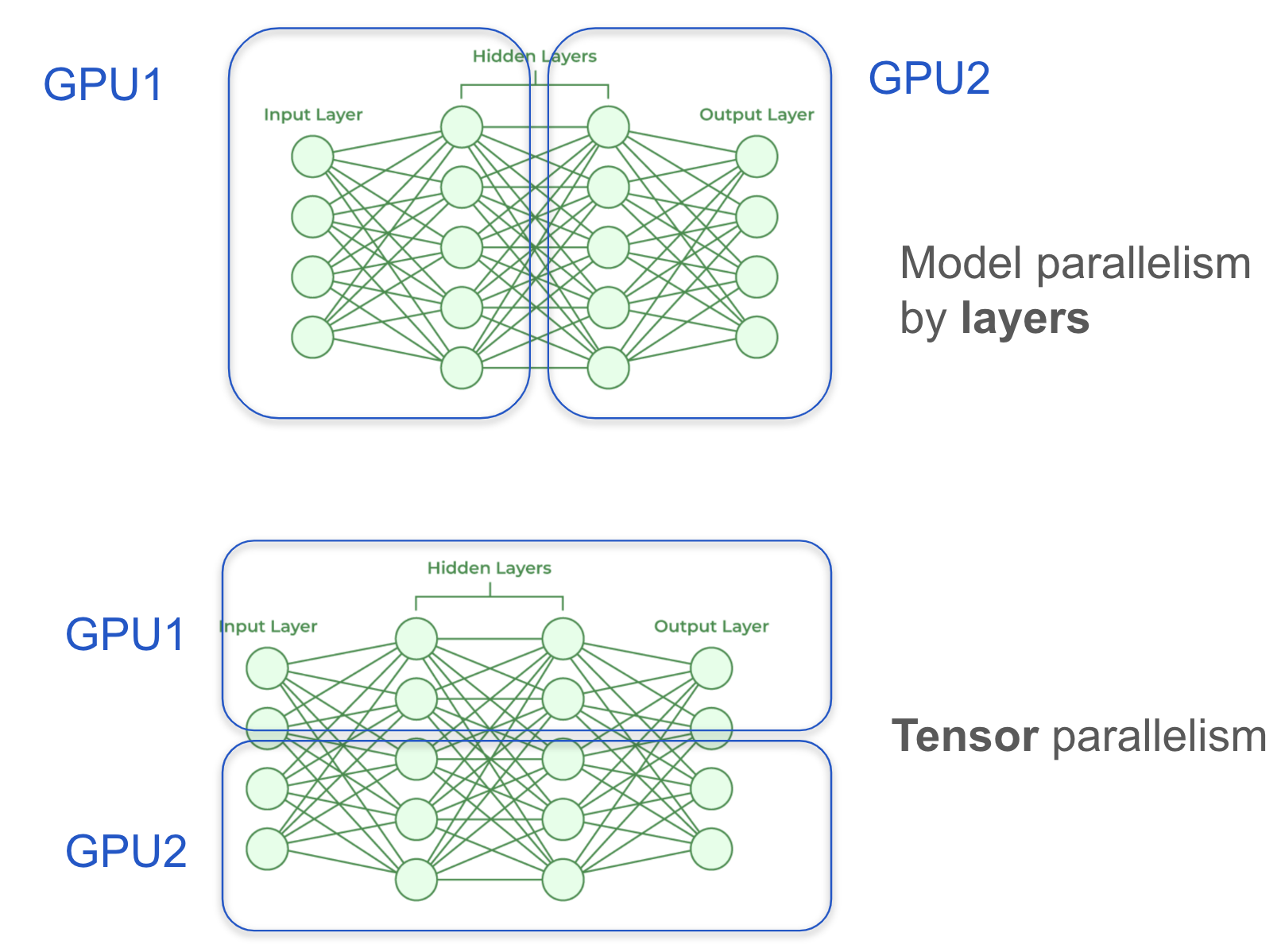
- 层式模型并行(上图):每个GPU负责层的子集,按顺序将激活传递给下一个GPU。
- 张量并行(下图):不是 按层 切割模型,而是在每一层内 水平拆分。每个GPU处理同一层计算的一部分,减少内存开销,同时实现高效的并行执行。
关键挑战与创新
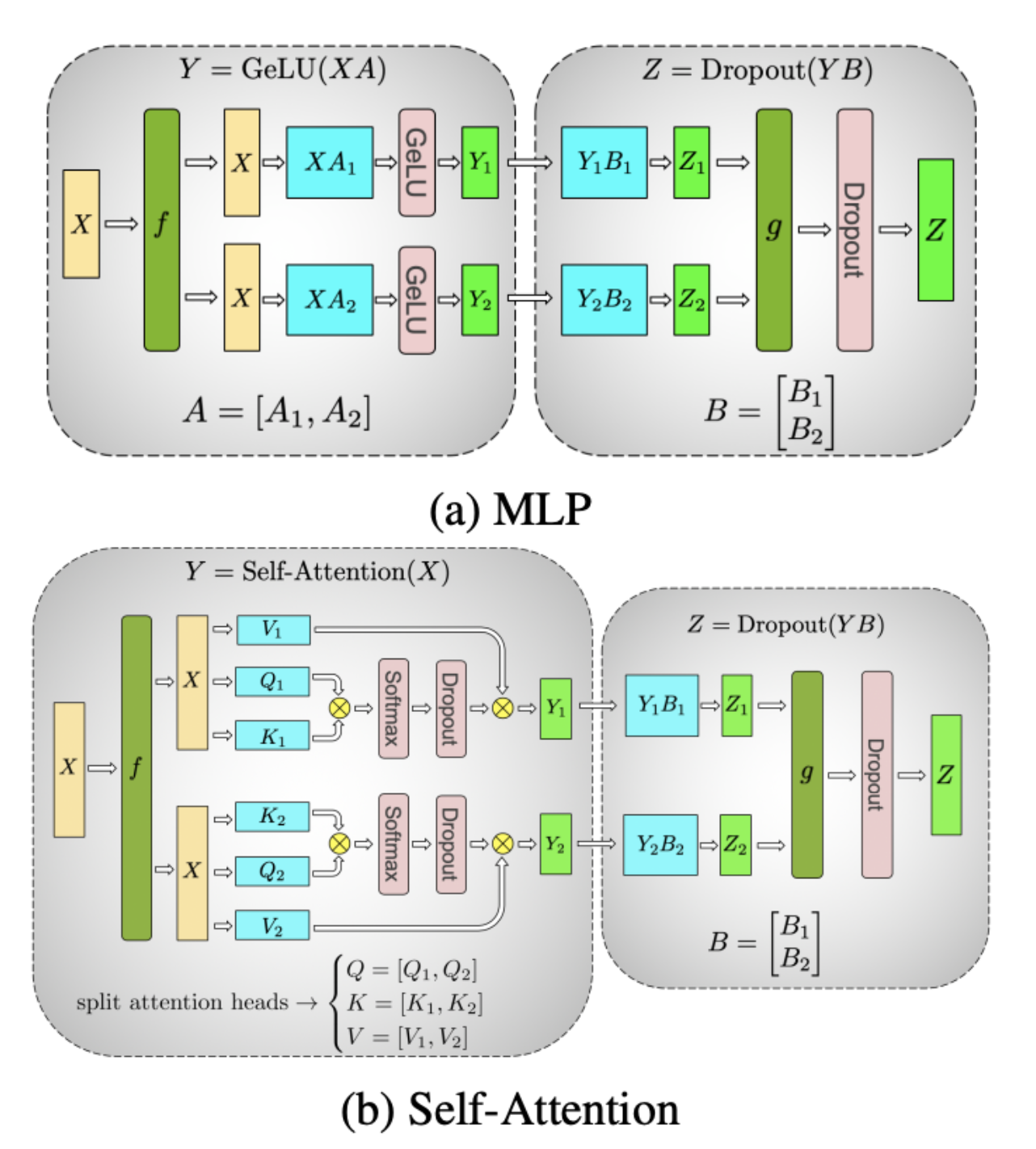
- 共享计算:某些组件,如嵌入和层归一化,必须在GPU之间保持同步以保持一致性。
- 高速互连:NVLink,NVIDIA的高带宽GPU互连,对于张量并行中 GPU之间的快速通信 至关重要。
Megatron的 张量并行 为 扩展模型超出单个GPU的内存限制 铺平了道路,这是训练 GPT-3及以后 的关键进步。今天,混合并行(结合张量、流水线和数据并行)是高效训练 大规模 神经网络的标准。
要深入了解,请查看Megatron论文:🔗 Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
专家并行 (Expert Parallelism)
我原本不打算讨论 专家并行 (EP),但随着 DeepSeek 开源 DeepEP,值得重新审视。
专家并行的起源
专家并行 (EP) 源于 Switch Transformer 论文 (2021),该论文介绍了用于深度学习模型的 混合专家 (MoE) 扩展。这种方法通过每次前向传递仅激活”专家”层的子集来实现高效的 万亿参数 模型,显着降低计算成本。一些有趣的事实:
- 第一和第二作者:William Fedus 和 Barret Zoph 都去了 OpenAI。鉴于他们的MoE专业知识,关于 GPT-4o利用MoE 的传言似乎相当合理。
- 最后作者:Noam Shazeer,Transformer的共同发明人,后来创立了 Character.AI。有趣的是,Google最近收购了Character.AI,将他带回了Google生态系统。
来自DeepSeek的DeepEP
DeepSeek的 DeepEP 现在在Deepseek开源周期间开源,为社区带来了高性能的 MoE风格专家并行。
回顾Deepseek V3有
- 256个专家,每个token选择 前8个专家。
- 此设置与 Mistral的MoE(总共8个专家) 截然不同。
- 在 DeepEP 中,每个单独的专家相对 较浅,但系统的专家路由允许 更高的总专家数,同时保持推理效率。
- 一个合理的估计是 每个GPU处理 ~1-4个专家。
另外,请注意 每个token由8个专家生成。但我们可以看出 硅基专家比碳基专家协作得更好,是吧?🤖🔥
未来阅读
顶级资源
Hugging Face: 超大模型训练手册
查看”寻找最佳训练配置”部分以获取实用指南。
Hugging Face Picotron: 用于教育目的的极简4D并行分布式训练框架
Stanford CS336 assignment2: 分布式数据并行训练
相关论文
Alexnet, GPipe, Megatron, Switch Transformer已在上面介绍。
我过去常列出一些,但这并不是个好主意。
询问LLM(主动学习更有效)。
结尾
Hugging Face文章提供了根据模型大小和GPU数量应使用的内容的良好总结。
我不认为记住这些细节是切合实际的,更重要的是,我不认为你应该记住。培养直觉就足够了。
我想再次强调,这是 实验科学 - 训练LLM炼金术的另一个维度。在你实验之前,你不会知道什么能产生最高的吞吐量。
让我们一起复习,确保你有所收获: