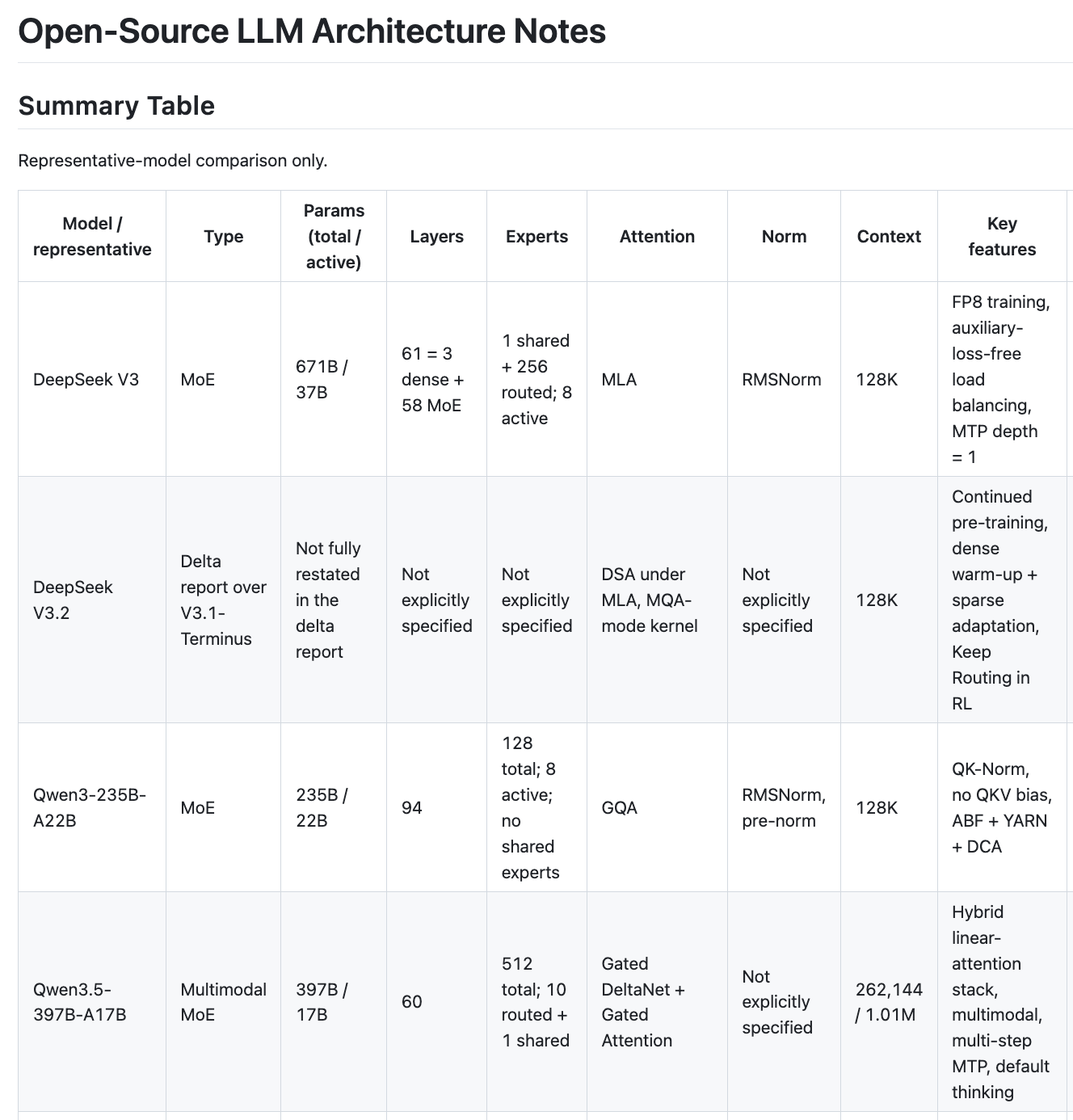
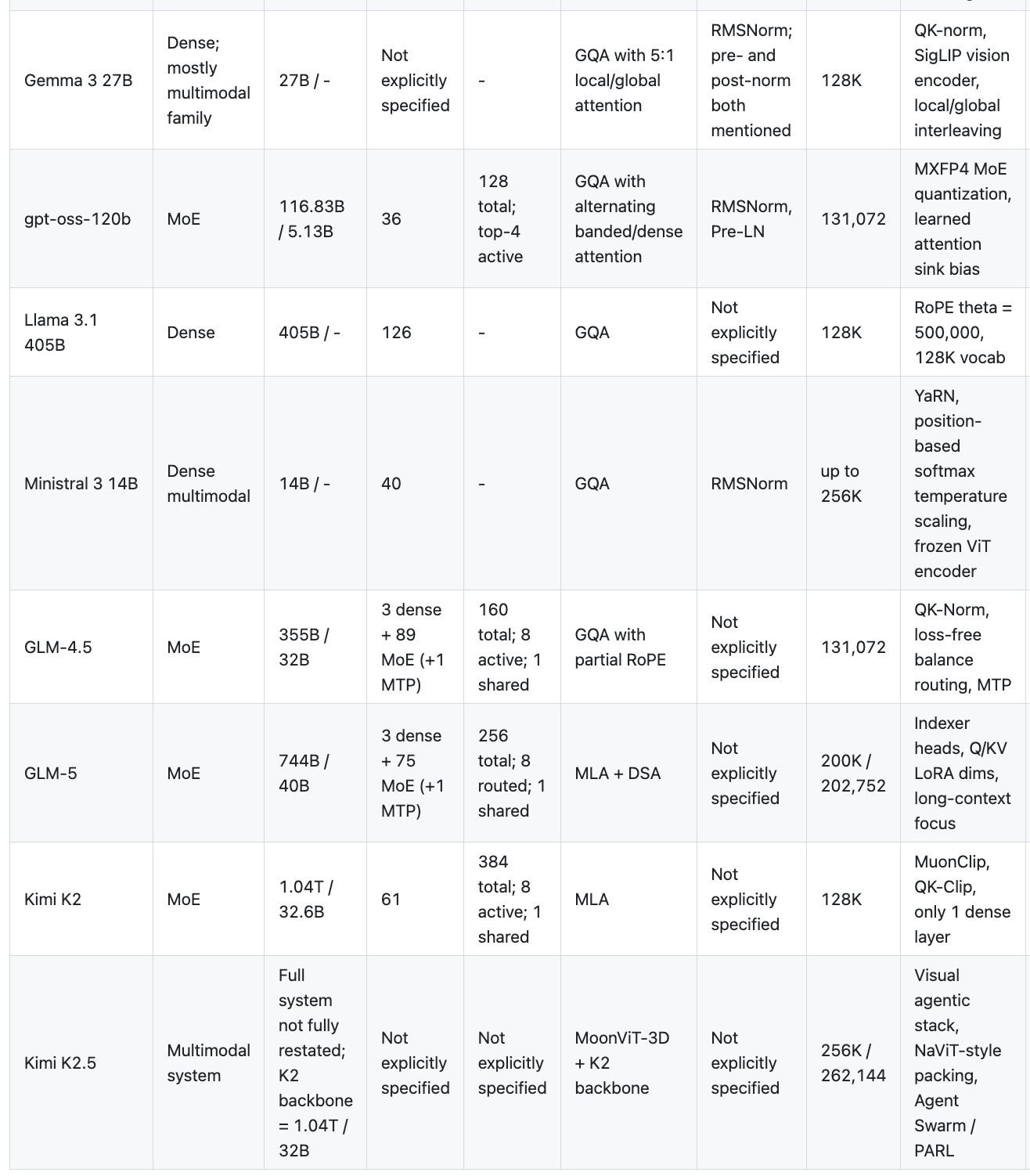
I spent part of a weekend afternoon, with a lot of help from AI, reading through technical reports of the major open-source LLMs released over the past year: DeepSeek V3/V3.2, Qwen 3/3.5, Gemma 3, Llama 3.1, GLM-4.5/5, Kimi K2/K2.5, gpt-oss, and Ministral 3.
My main takeaway is simple: the frontier is converging on a fairly standard backbone recipe, and most of the real differentiation has moved into attention, long-context handling, and systems work.
For the detailed model-by-model notes, see my architecture notes.
The Backbone Is Converging
Across the frontier models, the backbone recipe is starting to look familiar. DeepSeek V3 (671B/37B active), Qwen 3 (235B/22B), GLM-5 (744B/40B), Kimi K2 (1T/32B), and even OpenAI’s first open model gpt-oss (117B/5B) all pack huge total parameter counts while activating only a small fraction per token.
The dense holdouts are Llama 3.1 (405B dense, all active all the time), Gemma 3 (27B dense), and Ministral 3 (14B dense). They are still competitive, but they sit outside the main scaling pattern.
What matters more is that the MoE recipe itself is converging: a few dense layers at the bottom, then mostly expert layers; top-8 routing is common; and some families add one shared expert. That pattern shows up in DeepSeek, GLM, and Kimi with surprisingly little variation.
The Attention Wars: MLA vs GQA
Here’s where things get interesting. There’s a clear split:
- GQA camp: Qwen 3, Gemma 3, Llama 3.1, Ministral 3, GLM-4.5, gpt-oss
- MLA camp: DeepSeek V3, GLM-5, Kimi K2
GQA is the safe, well-understood choice. MLA (Multi-head Latent Attention) is the DeepSeek innovation that compresses the KV cache aggressively. It’s more complex, but the KV-cache savings at inference are massive. GLM-5 switching from GQA (GLM-4.5) to MLA is a strong signal — it means teams that try MLA don’t go back.
And then there’s Qwen 3.5, which went full wildcard: Gated DeltaNet + Gated Attention, a hybrid linear-attention-plus-traditional-attention stack. This is the most architecturally adventurous model in the set. 512 experts, 1M+ token context, multi-step MTP. If this works well at scale, it might be the next paradigm shift after MoE.
Everyone Wants Longer Context
- Qwen 3.5: 1M tokens natively
- GLM-5: 200K
- Ministral 3: 256K
- Most others: 128K
128K is now table stakes. The techniques are well-known: RoPE with high base frequency, YaRN, ABF, DCA. The more interesting story is sparse attention — DeepSeek’s DSA (DeepSeek Sparse Attention) shows up in both V3.2 and GLM-5, which suggests it actually works for long context. Instead of attending to everything, you learn which parts matter.
The Small Details That Have Standardized
At the block level, there is surprisingly little disagreement now:
- RMSNorm everywhere. Not a single model in this set uses LayerNorm.
- SwiGLU as the FFN activation. It’s in DeepSeek, Llama, Kimi, gpt-oss, Ministral.
- RoPE for positional encoding. No one is experimenting with learned positions anymore.
- QK-Norm is the new trend for training stability — Qwen, Gemma, and GLM all adopted it, while Kimi went with QK-Clip instead.
- MTP (Multi-Token Prediction) keeps showing up: DeepSeek, Qwen 3.5, GLM-4.5, GLM-5. It seems to help, though the implementations vary.
Multimodal Is Now Default
Qwen 3.5, Gemma 3, Ministral 3, Kimi K2.5 — all multimodal. The approach is also converging: keep the language backbone intact, bolt on a vision encoder + projector. Nobody is redesigning the Transformer from scratch for multimodality. Kimi K2.5 is the most ambitious here with its MoonViT-3D and agentic stack, but the language backbone is still just K2 underneath.
What Surprised Me
gpt-oss is tiny. 117B total, 5B active — the smallest MoE in this set by far. OpenAI clearly wanted to release something efficient rather than frontier-pushing. The MXFP4 quantized MoE weights are interesting though.
DeepSeek V3 FP8 training is still the most impressive infrastructure story. Training a 671B MoE in FP8 mixed precision is not easy, and nobody else has reported doing it at this scale.
Kimi K2 is the biggest model at 1T total parameters with only 1 dense layer. That’s extreme sparsity. The MuonClip optimizer and QK-Clip for stability are novel solutions to problems that come with this level of sparsity.
My Take
The open-source LLM world is moving fast, but it is not chaos. It is convergence. MoE with ~8 active experts, RMSNorm, SwiGLU, RoPE, and 128K+ context is becoming a standard recipe. The frontier differentiation is now in attention design (MLA vs GQA vs hybrid), training infrastructure (FP8, MXFP4), and post-training (RL, reasoning, agents).
If I had to bet on the most influential architecture decision for the next generation, it would be the MLA vs hybrid-linear-attention question. GQA is a fine baseline, but the KV-cache problem only gets worse as context gets longer. Something has to give.
The Chinese labs (DeepSeek, Qwen, GLM, Kimi) are shipping at an impressive pace and with real technical depth. MLA, DSA, DeltaNet hybrids, and auxiliary-loss-free routing are not small variations. They are substantive architecture decisions, and they are pushing the frontier forward.