周末的一个下午,在 AI 的大力协助下,我花了一些时间阅读了过去一年发布的主要开源大语言模型(LLM)的技术报告:DeepSeek V3/V3.2、Qwen 3/3.5、Gemma 3、Llama 3.1、GLM-4.5/5、Kimi K2/K2.5、gpt-oss 以及 Ministral 3。
我的主要收获很简单:前沿模型正在向一种相当标准的骨干网络方案收敛,而大多数真正的差异化已经转移到了注意力机制、长上下文处理以及系统工程上。
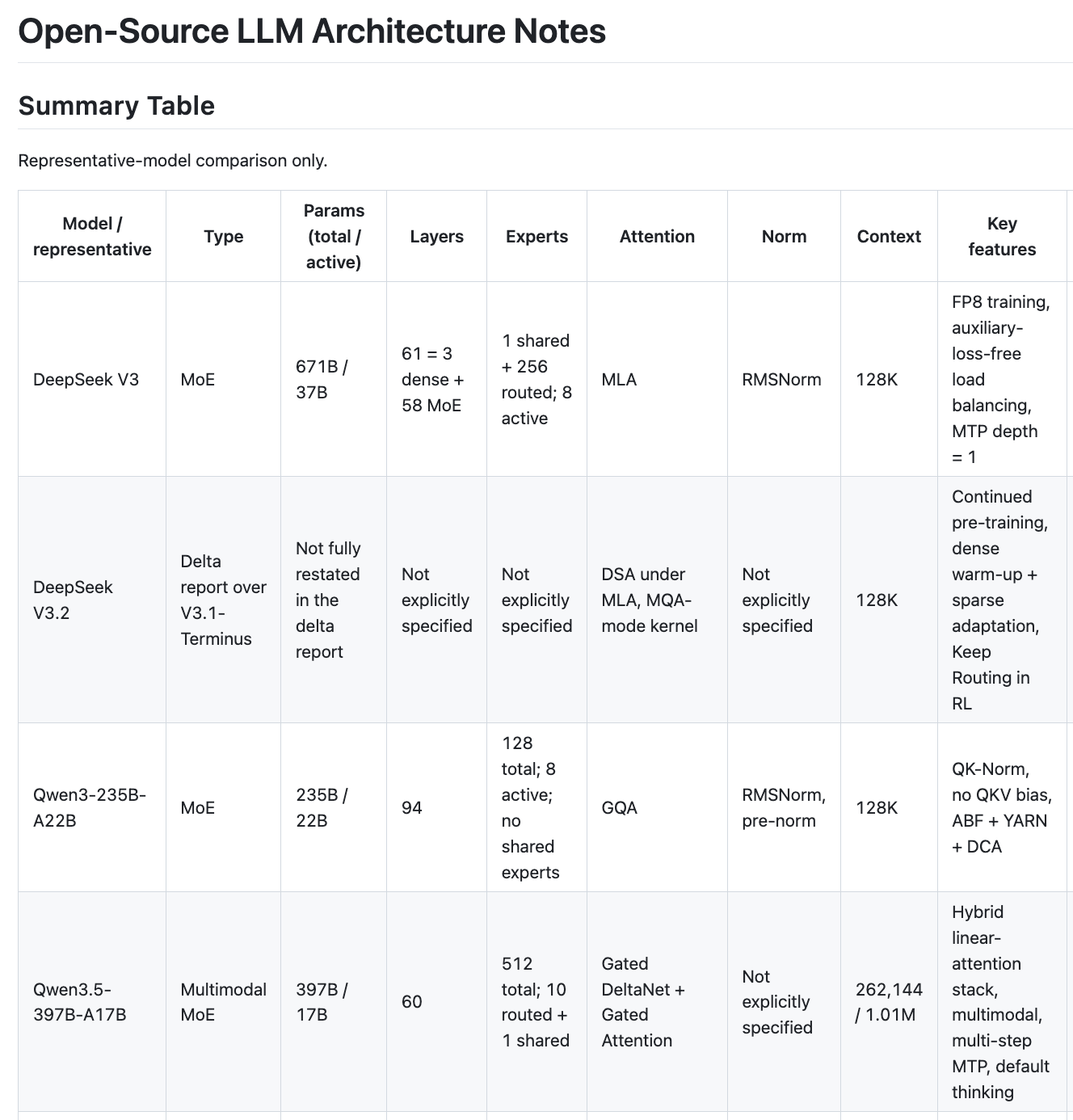
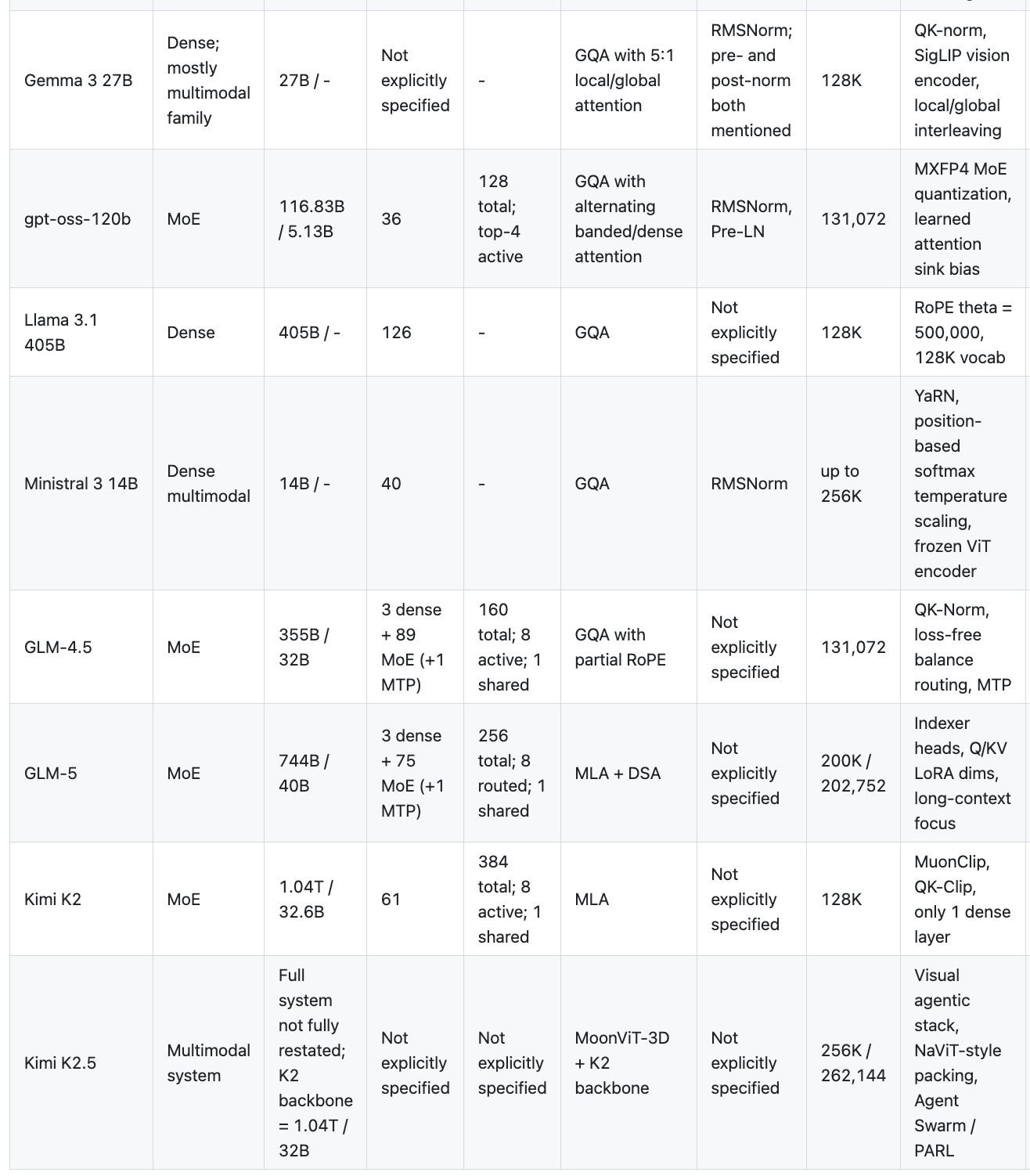
有关各个模型的详细笔记,请参阅我的架构笔记。
骨干网络正在收敛
在这些前沿模型中,骨干网络方案开始变得似曾相识。DeepSeek V3(总参数 671B/激活 37B)、Qwen 3(235B/22B)、GLM-5(744B/40B)、Kimi K2(1T/32B),甚至 OpenAI 的首个开源模型 gpt-oss(117B/5B),都拥有庞大的总参数量,但在每个 token 上只激活极小一部分。
坚持使用稠密模型的有 Llama 3.1(405B 稠密,始终全部激活)、Gemma 3(27B 稠密)和 Ministral 3(14B 稠密)。它们依然具有竞争力,但已经游离于主流的扩展模式之外。
更重要的是,MoE(混合专家)方案本身也在收敛:底部是几层稠密层,然后主要是专家层;Top-8 路由很常见;一些模型系列还会添加一个共享专家。这种模式在 DeepSeek、GLM 和 Kimi 中都有出现,且差异小得令人惊讶。
注意力之战:MLA 对决 GQA
这正是事情变得有趣的地方。这里出现了明显的分歧:
- GQA 阵营:Qwen 3、Gemma 3、Llama 3.1、Ministral 3、GLM-4.5、gpt-oss
- MLA 阵营:DeepSeek V3、GLM-5、Kimi K2
GQA 是安全且被充分理解的选择。MLA(多头潜在注意力)是 DeepSeek 的创新,它极大地压缩了 KV 缓存。它虽然更复杂,但在推理时节省的 KV 缓存是巨大的。GLM-5 从 GQA(GLM-4.5)转向 MLA 是一个强烈的信号——这意味着尝试过 MLA 的团队就不会再回头了。
然后是 Qwen 3.5,它完全不按套路出牌:门控 DeltaNet + 门控注意力(Gated DeltaNet + Gated Attention),这是一种线性注意力加传统注意力的混合架构。这是这批模型中在架构上最大胆的一个。512 个专家、1M+ token 上下文、多步 MTP。如果这种架构在扩大规模后表现良好,它可能会成为继 MoE 之后的下一个范式转变。
大家都想要更长的上下文
- Qwen 3.5:原生 1M tokens
- GLM-5:200K
- Ministral 3:256K
- 大多数其他模型:128K
128K 现在已经是标配了。相关技术大家都很熟悉:高基础频率的 RoPE、YaRN、ABF、DCA。更有趣的故事在于稀疏注意力(sparse attention)——DeepSeek 的 DSA(DeepSeek 稀疏注意力)在 V3.2 和 GLM-5 中都有出现,这表明它在长上下文处理上确实有效。与其关注所有内容,不如学习哪些部分才是重要的。
已经标准化的微小细节
在 Block 层面上,现在令人惊讶地几乎没有分歧:
- 随处可见的 RMSNorm。这批模型中没有一个使用 LayerNorm。
- SwiGLU 作为 FFN 激活函数。DeepSeek、Llama、Kimi、gpt-oss、Ministral 都在用。
- RoPE 用于位置编码。再也没有人尝试使用可学习的位置编码了。
- QK-Norm 是训练稳定性的新趋势——Qwen、Gemma 和 GLM 都采用了它,而 Kimi 则选择了 QK-Clip。
- MTP(多 Token 预测)不断出现:DeepSeek、Qwen 3.5、GLM-4.5、GLM-5。它似乎确实有帮助,尽管各家的实现方式有所不同。
多模态现已成为默认配置
Qwen 3.5、Gemma 3、Ministral 3、Kimi K2.5——全部都是多模态模型。其实现方法也在收敛:保持语言骨干网络完整,外挂一个视觉编码器 + 投影层。 没有人为了多模态而从头重新设计 Transformer。Kimi K2.5 在这方面最具野心,配备了 MoonViT-3D 和智能体架构,但底层的语言骨干网络依然只是 K2。
让我感到惊讶的地方
gpt-oss 非常小。 总参数 117B,激活 5B——这是这批模型中迄今为止最小的 MoE。显然,OpenAI 想要发布的是一个高效的模型,而不是为了推动前沿。不过,MXFP4 量化的 MoE 权重倒是很有意思。
DeepSeek V3 的 FP8 训练 依然是最令人印象深刻的基础设施故事。在 FP8 混合精度下训练一个 671B 的 MoE 绝非易事,而且还没有其他团队报告过在这种规模下实现过。
Kimi K2 是最大的模型,总参数量达到 1T,却只有 1 层稠密层。这是极度的稀疏性。用于保持稳定性的 MuonClip 优化器和 QK-Clip,是解决这种级别稀疏性所带来问题的新颖方案。
我的看法
开源大语言模型领域发展迅速,但它并非一片混乱,而是在走向收敛。 激活约 8 个专家的 MoE、RMSNorm、SwiGLU、RoPE 以及 128K+ 上下文正在成为标准方案。前沿的差异化现在体现在注意力机制设计(MLA vs GQA vs 混合架构)、训练基础设施(FP8、MXFP4)以及后训练(强化学习、推理、智能体)上。
如果让我押注下一代最具影响力的架构决策,那将会是 MLA 与混合线性注意力 之间的问题。GQA 是一个很好的基线,但随着上下文变得越来越长,KV 缓存问题只会变得更糟。总得有所取舍。
中国的实验室(DeepSeek、Qwen、GLM、Kimi)正以惊人的速度发布模型,并且具备真正的技术深度。MLA、DSA、DeltaNet 混合架构以及无辅助损失路由(auxiliary-loss-free routing)绝非微小的变动。它们是实质性的架构决策,正在推动前沿不断向前发展。